
Audiokinetic and ReadSpeaker are excited to bring a deep integration of speechEngine into the Wwise pipeline, allowing developers to harness the power and flexibility of on-device text to speech in their game. speechEngine for Wwise is a cross-platform solution and seamlessly integrates into the game development workflow.
speechEngine's runtime capabilities give developers full control, enabling real-time conversion of in-game text to speech. Whether they’re looking to enhance accessibility with UI narration and audio descriptions, add speech to multiplayer interactions, or build narrative experiences, speechEngine will enable developers to add dynamic, natural-sounding speech to their game.
On-device Processing
The advantage of speechEngine lies in its on-device capabilities. By using a CPU-based computing framework we are able to synthesize speech locally on the device. This means that there is no network connection required in any step of the process. Using optimized algorithms for inference, along with lightweight models, speechEngine produces speech on a single thread of the CPU with fast response times. At the same time, we are able to keep the footprint of our technology small, with each voice engine requiring ~10-15 MB of memory. Additionally, we have made this technology available across platforms, allowing cross-platform deployment.
Author, Export and Dynamically Adjust
The speechEngine integration for Wwise adds voice control parameters directly to the Authoring interface, enabling fine tuning of the voice profile along with the vast range of effects provided by Wwise to further customize the sound of the voice. When exporting to a SoundBank, you control the voice engine at runtime. By sending text input to the plug-in through the Wwise SDK and playing the voice, speechEngine immediately reads the text aloud. Furthermore, you can access controls for pitch, speed and more utilizing RTPCs. For more fine-grained control, Speech Synthesis Markup Language (SSML) can be used as text input for further customization.
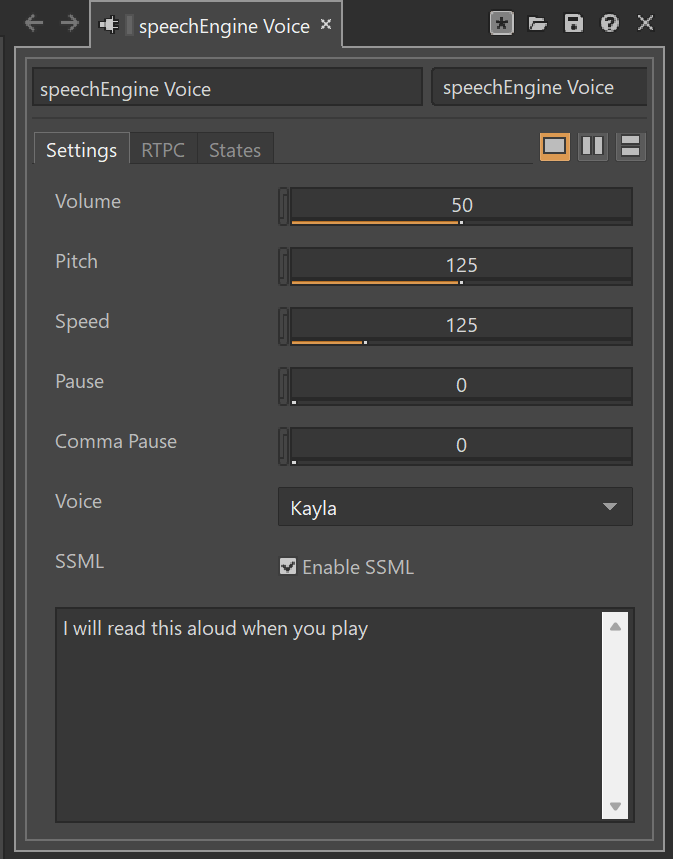
Speech Synthesis Markup Language (SSML)
SSML allows you to further customize how text will be read. Using the simple markup language syntax of SSML you can achieve a multitude of effects, such as putting emphasis on a certain part of the speech, like in these examples:
Example 1: "Listen carefully!"
<emphasis level=”strong”>Listen carefully!</emphasis>
KaylaMollySophie |
|
Example 2: Inserting breaks
We are in dangerous territory <break time=”200ms”> proceed carefully from here on
KaylaMollySophie |
|
Example 3: Change how the text is interpreted
<say-as interpret-as="characters">wasd</say-as>
KaylaMollySophie |
|
Example 4: Spelling words out phoneme by phoneme:
Hello <phoneme alphabet="ipa" ph="wɜːld">world</phoneme>
KaylaMollySophie |
|
For details on the full range of SSML possibilities, see the official W3C specification: https://www.w3.org/TR/speech-synthesis/#S3.2.3
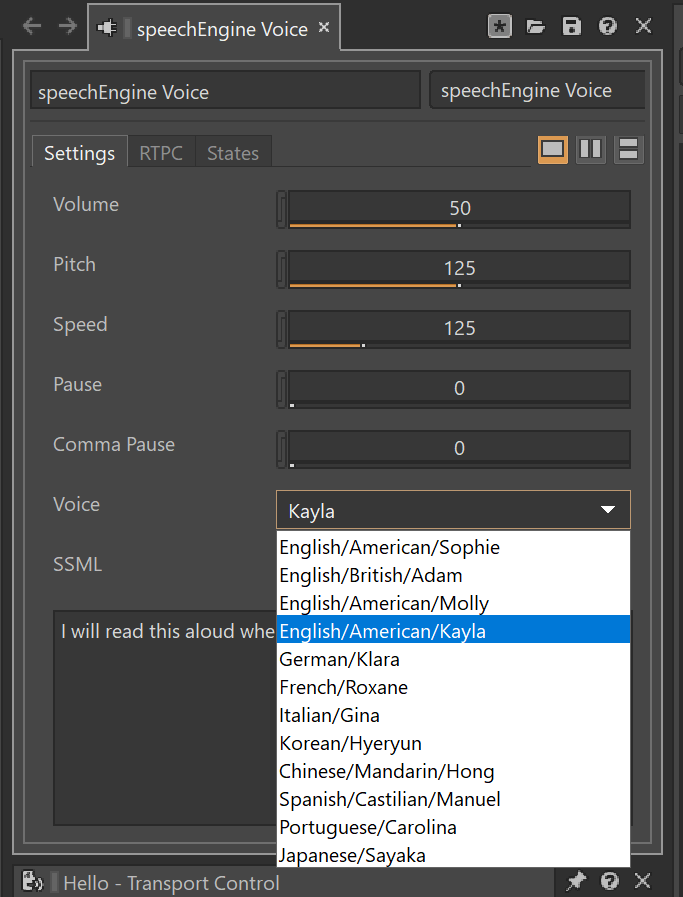
Voice Library
ReadSpeaker offers a broad range of voice options, with a library of over 115 voices in more than 40 languages. The initial speechEngine for Wwise plug-in release ships with 12 unique-sounding voices in 10 different languages. We plan to continue to expand the selection of languages and voices in future releases.
What Will You Create With speechEngine?
We invite game developers to explore the power of speechEngine for Wwise. Connect with us on Discord or drop us an email (gaming@readspeaker.com).

ReadSpeaker is committed to delivering ethical AI-powered voice solutions. Learn more about their approach to ethical AI voice in gaming here.

Comments