
Introduction
Dans ce document, je vais tenter d'expliquer les différents principes que nous avons appliqués lors du profiling et de l'optimisation audio de notre jeu, Scars Above. L'objectif est d'aider les autres concepteurs sonores en leur donnant un aperçu des processus que nous avons appliqués et en leur proposant des conseils sur la manière d'aborder et de planifier l'optimisation audio.
Même si ce document ne s'adresse pas exclusivement à des collègues très expérimentés, une certaine connaissance de base de Wwise et d'Unreal Engine, ainsi que de leurs flux de travail, est nécessaire pour une meilleure compréhension. Je pars du principe que vous, lecteur, avez de l'expérience dans l'importation, l'organisation et l'intégration de sons dans l'outil de création Wwise et l'éditeur Unreal.
Scars Above a été compilé sur notre moteur de jeu personnalisé, basé sur la version 4.27.2 d'Unreal Engine et sur la version 2021.1.9.7847.2311 de l'intégration Unreal de Wwise.
Table des matières
- Principes de l'optimisation
- Restrictions de notre jeu
- Profiling
- Optimisation
- Conclusion
- Liens utiles
Principes de l'optimisation
L’optimisation est un processus important lorsqu’on travaille sur un jeu, et qui intervient, dans la plupart des cas, à un stade avancé de la production. Cependant, il est recommandé de planifier l’optimisation dès les premières étapes de développement, car il est utile de définir un budget audio et de bien comprendre les limites de notre jeu. Respecter les limites prédéfinies garantit que le jeu fonctionnera comme prévu sur toutes les plateformes et dans toutes les configurations. Lorsque l’audio fonctionne correctement, il n’y a pas de problèmes de son. Si nous dépassons le budget audio, une série de problèmes peuvent apparaître, comme des coupures soudaines dans la bande son, des glitches audio ou des baisses de framerate qui peuvent nuire à l'expérience de jeu. C'est pourquoi il est essentiel de constamment viser les meilleures performances de jeu possibles, en planifiant et en optimisant l'audio.
En ce qui concerne l’audio, plusieurs approches permettent d’améliorer la fluidité du jeu. Certaines consistent à réduire l’empreinte mémoire des assets audio, d’autres à diminuer la charge sur le thread audio. La plupart de ces pratiques permettent d'améliorer à la fois l'usage mémoire comme la charge du processeur.
Puisque nous travaillons avec Wwise et Unreal Engine, des ajustements doivent être pris des deux côtés. Ci-dessous, je vais passer en revue toutes les étapes que nous avons suivies pour optimiser l'audio de Scars Above.
Restrictions de notre jeu
Alors que nous étions à un stade avancé de la production, nous avons commencé à nous intéresser à la manière dont l’audio influait sur les performances du jeu. Après en avoir discuté avec notre équipe de programmation, nous nous sommes mis d'accord sur la façon de définir le budget audio pour chaque plateforme.
D'un point de vue général, la principale préoccupation pour notre jeu reposait sur les problèmes d'espace mémoire (Out Of Memory, ou OOM) sur les plateformes de huitième génération. Les ressources mémoire sont relativement limitées sur ces plateformes, notamment sur les versions de base de la PlayStation 4 et de la Xbox One (la RAM utilisable sur les plateformes de génération 8 étant environ deux fois moindre que sur celles de génération 9). Nous avons convenu que le budget mémoire dédié à l'audio sur génération 8 et sur les PC de configuration modeste ne devait pas dépasser 250 Mo au total.
L’audio peut également solliciter fortement le processeur. De nombreux calculs sont effectués à chaque image, et comme nous avons opté pour une configuration complexe utilisant Spatial Audio pour l'ensemble du jeu, ces calculs peuvent s'avérer très coûteux, en particulier sur les plateformes de génération 8. Le budget CPU a été laissé à notre discrétion, puisque nous pouvons facilement analyser la consommation des threads audio via le Profiler Wwise. Nous avons décidé que l'usage total du CPU pour le thread audio devait avoir une charge maximale de 100 %, avec une moyenne inférieure à 50 % sur génération 8, et une moyenne inférieure à 30 % sur génération 9 et sur PC.
Résumé des budgets
|
|
Mémoire totale des médias |
Total des pics CPU |
Usage moyen du CPU |
|
Génération 8 |
250Mo |
100% |
50% |
|
Génération 9 |
250Mo |
80% |
30% |
|
PC |
250Mo |
80% |
30% |
Tableau 1 : Limitations du budget mémoire et CPU pour l'audio sur toutes les plateformes
Problèmes audio liés à la mémoire ou au processeur
Les problèmes audio peuvent se manifester de plusieurs manières pendant le jeu. J'aborderai ici les quatre erreurs les plus courantes : le manque d'espace mémoire (Out Of Memory, OOM), les pics d'utilisation du processeur, les défaillances de voix (Voice Starvation) et les défaillances de sources (Source Starvation).
Mémoire insuffisante (Out Of Memory, OOM)
Le manque d'espace mémoire (OOM) se produit lorsque le système ne peut plus allouer de mémoire aux nouveaux processus. Cela se produit lorsque nous dépassons soit la mémoire physique maximale disponible sur la plateforme, soit la mémoire maximale allouée au moteur sonore (définie dans le paramètre d'initialisation AkMemSettings::uMemAllocationSizeLimit). Les problèmes d'espace mémoire peuvent entraîner des plantages du système en cas de dépassement de la mémoire physique, ou des échecs d'initialisation du moteur sonore, des échecs de chargement des SoundBanks, des sauts de transitions ou des échecs de lecture du son en cas de dépassement de la mémoire allouée au moteur sonore.
Les causes des erreurs d'espace mémoire peuvent être multiples. Lorsqu'il est géré correctement, le son n'occupe généralement qu'une petite partie de la consommation totale de la mémoire. Néanmoins, nous devrions toujours veiller à ne pas dépasser les limites de mémoire du moteur sonore convenues lors de la définition des budgets pour notre jeu.
Pics d'utilisation du CPU
Le thread audio, qui gère la plupart des processus concernant l'audio, est séparé du thread du jeu et est continuellement occupé par le moteur audio de Wwise. Toutes les mesures du CPU affichées dans le Profiler de Wwise sont associées à l'usage du thread audio.
Dans les situations où le thread audio est incapable de rendre tous les sons dans une seule image, son usage dépasse 100% dans le Profiler Wwise. Cela peut se produire pour diverses raisons, principalement lorsque les exigences de calcul audio à cette image sont excessives pour le thread audio. Dans Scars Above, les principales cause des pics d'usage du CPU étaient les calculs des chemins de propagation de Spatial Audio et le chargement et déchargement simultanés d'un grand nombre d'émetteurs audio.
Les pics de CPU uniques qui ne sont pas excessivement élevés ou qui ne se répètent pas fréquemment peuvent ne pas entraîner de problèmes audibles. Par conséquent, nous pouvons sans risque fixer la limite totale des pics d'usage du CPU à 100% (tableau 1). Cependant, si les pics de CPU sont excessivement élevés (mesurés en centaines ou même en milliers) ou s'il y a de nombreux pics consécutifs, le moteur audio peut introduire des glitches audio ou des coupures sonores.
Défaillances de voix (Voice Starvation)
Les erreurs de défaillances de voix se produisent lorsque le thread audio est incapable de rendre tous les sons d'une image pendant plusieurs images consécutives, ce qui entraîne un usage total du CPU de 100%. Ces erreurs se manifestent par des coupures sonores et des glitches. Au cours de notre développement, nous avons rencontré des erreurs de Voice Starvation sur les consoles de génération 8, en particulier sur la plateforme PS4 de base, dans les zones du jeu comportant beaucoup de géométrie Spatial Audio complexe et de nombreux émetteurs nécessitant des calculs à chaque image. La réduction de la complexité de Spatial Audio et la limitation du nombre d'émetteurs chargés simultanément ont grandement contribué à la résolution des erreurs de Voice Starvation.
Défaillances de sources (Source Starvation)
Les erreurs de défaillances de sources sont liées à la mémoire plutôt qu'au CPU et se produisent lorsque les sons qui sont lus directement depuis le disque (stream) ne peuvent pas fournir de données au Streaming Manager en temps voulu. Cela peut se produire pour diverses raisons, souvent lorsqu'il y a trop de fichiers lus en stream simultanément, ou lorsque le disque (le périphérique d'E/S) n'est pas en mesure de traiter toutes les données simultanément en raison de sa lenteur. Cela se manifeste à nouveau par des coupures sonores, en particulier pour les sons en cours de stream. Bien que des ajustements sur certains paramètres d'E/S puissent contribuer à réduire les erreurs de défaillances de sources, la solution la plus efficace consiste à limiter le nombre de sons lus simultanément en stream à partir du disque (de plus amples détails sur le stream seront abordés plus loin dans le document).
Profiling
Le profiling est une étape essentielle du processus d'optimisation. Lorsque nous commençons à optimiser le jeu, il est crucial d'évaluer l'état actuel de la consommation de la mémoire et du CPU, ainsi que d'identifier les engorgements potentiels qui peuvent avoir un impact sur ces paramètres.
Il est important de noter que tous les tests doivent être effectués sur les builds Testing (test) ou Shipping (commercialisation), plutôt que dans l'éditeur Unreal ou le build Development (développement). Bien que les tests dans l'éditeur Unreal puissent fournir une compréhension générale du comportement du jeu, effectuer les tests dans la version appropriée permet d'obtenir les bonnes données de performance sur lesquelles s'appuyer pour l'optimisation audio.
Profiler de Wwise
Le Profiler de Wwise est notre principal outil pour évaluer les performances audio. Bien qu'il ne semble pas très intuitif à première vue, il fournit une grande variété de données qui offre un aperçu précieux de l'état actuel de l'audio et aide à identifier tout problème de performance qui pourrait avoir émergé pendant le jeu.
Pendant le profiling, nous nous concentrerons sur plusieurs paramètres CPU et mémoire, présentés dans la section Performance Monitor du Profiler accessible depuis le logiciel Wwise Authoring.
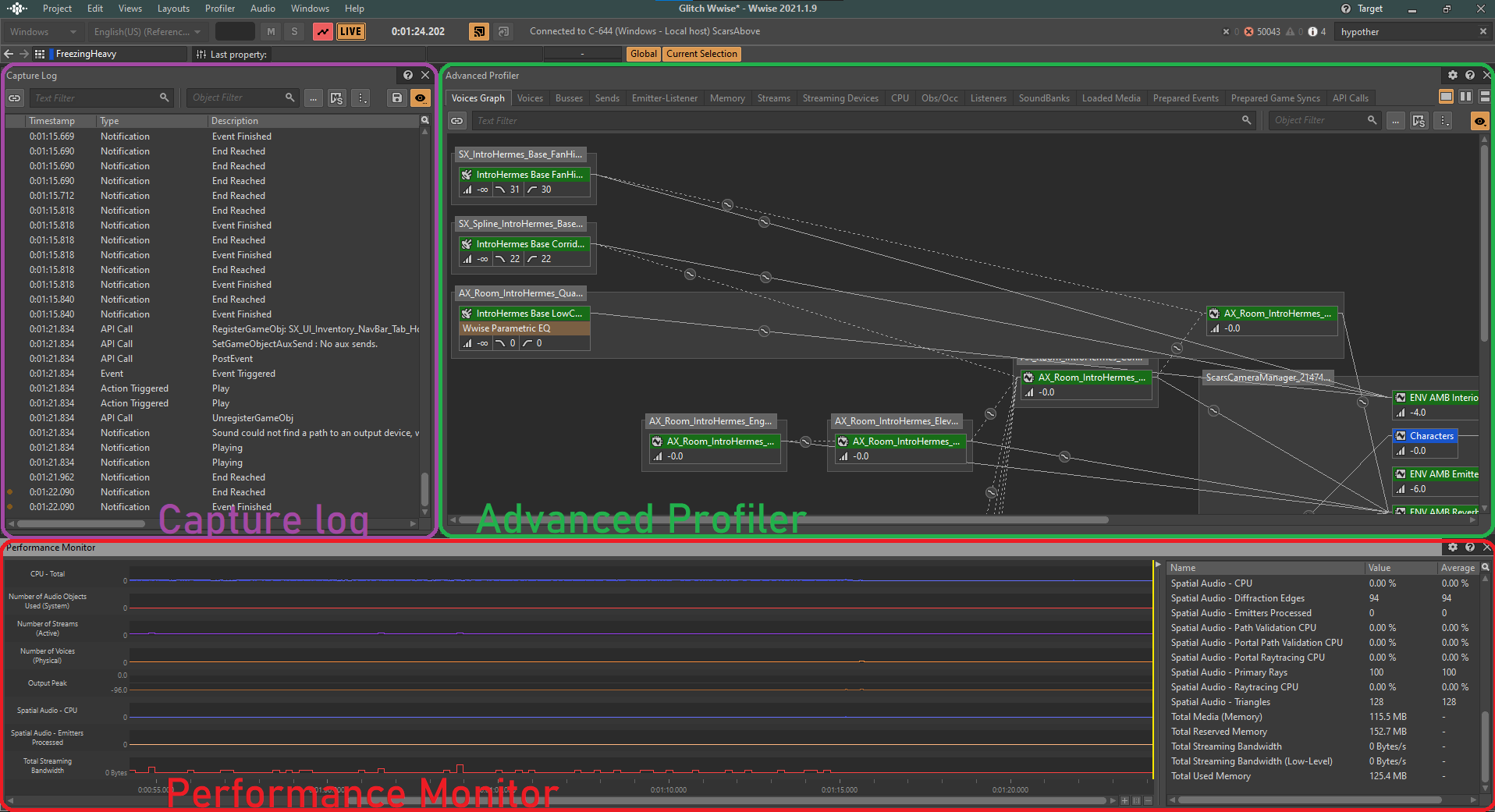
Image 1 : Fenêtre du Profiler de Wwise
À partir de la fenêtre Performance Monitor, nous pouvons observer en temps réel l'état de divers paramètres des performances sonores de notre jeu, à la fois visuellement et numériquement.
En surveillant ces paramètres importants, nous pouvons obtenir une image claire des performances audio de notre jeu à tout moment. Le Profiler présente un journal détaillé de toutes les actions qui se déroulent à chaque image du jeu. Pour analyser une image spécifique, nous pouvons déplacer le curseur jaune le long de la timeline, ce qui nous permet d'examiner n'importe quel point dans le temps :
Image 2 : Timeline de la fenêtre « Performance Monitor »
Si, par exemple, nous observons un pic d'usage du CPU ou une augmentation soudaine du nombre de voix audio sur le graphique, nous pouvons déplacer le curseur à ce moment précis et observer toutes les actions qui ont été déclenchées pendant cette image, ainsi que la consommation totale du CPU.
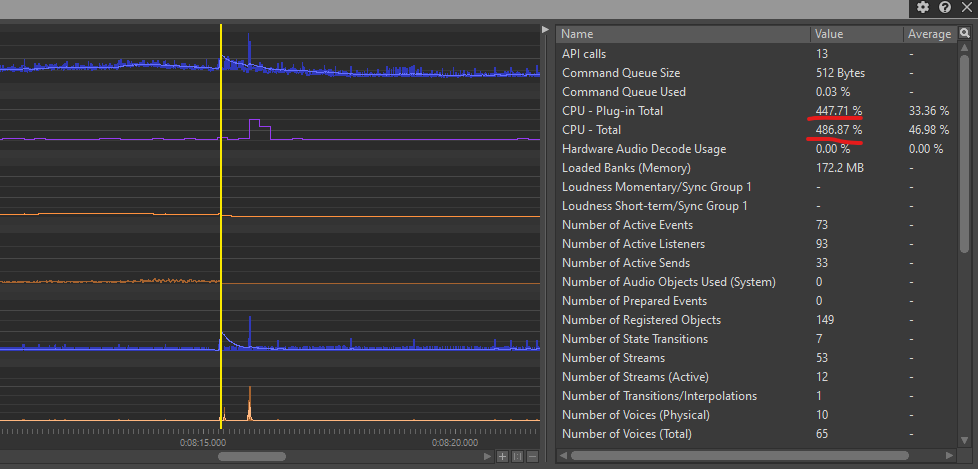
Image 3 : Exemple de pic d'usage du CPU
Paramètres du Profiler de Wwise
Les paramètres suivants servent d'indicateurs clés concernant les performances sonores dans notre jeu et sont généralement surveillés :
- CPU - Total : Affiche l'utilisation globale du CPU liée aux traitements audio ;
- CPU - Plug-in Total : Mesure l'utilisation du CPU spécifiquement attribuée aux plug-ins audio utilisés dans le jeu ;
- Number of Voices (Physical) (Nombre de voix audio physiques) : Indique le nombre total de voix audio actives jouées simultanément ;
- Number of Streams (Active) (Nombre de streams actifs) : Représente le nombre de streams audio actifs ;
- Spatial Audio - CPU : Indique l'utilisation du CPU spécifiquement liée aux traitements de Spatial Audio ;
- Spatial Audio - Emitters Processed (Spatial Audio - Traitement des émetteurs) : Indique le nombre d'émetteurs audio en cours de traitement pour les calculs de Spatial Audio ;
- Total Reserved Memory (Mémoire totale réservée) : Reflète la quantité de mémoire réservée aux assets audio ;
- Total Media (Memory) (Mémoire totale des médias) : Mesure la consommation totale de mémoire des assets médias.
Les paramètres mentionnés ci-dessus sont utilisés pour surveiller l'usage du CPU, à l'exception de Total Media (Memory) et Total Reserved Memory, qui surveillent l'usage de la mémoire.
Profiling depuis l'éditeur Unreal
Malheureusement, les données audio de Wwise ne sont pas clairement représentées dans l'éditeur Unreal. Wwise ne communique pas les données sur l'usage de la mémoire ou du CPU à Unreal Engine, ce qui limite nos possibilités de profiling à cet égard. Bien que des outils comme Unreal Insights ou Low-Level Memory Tracker soient utiles pour surveiller l'usage du CPU ou de la mémoire du côté de l'éditeur Unreal, ils ne fournissent pas d'information spécifiquement reliée aux assets et processus de Wwise.
Ce que nous pouvons faire, c'est utiliser l'Output Log (journal de sortie) d'Unreal pour identifier les erreurs causées par une mauvaise implémentation des sons. Dans Unreal, il est possible de recouper les messages du Message Log (journal de messages) associés au Profiler de Wwise avec l'Output Log. Les erreurs de Wwise affichées dans l'Output Log sont typiquement préfixées de « LogAkAudio », ce qui permet de filtrer les résultats et de faciliter la recherche de problèmes. Lorsque l'équipe d'Assurance Qualité reçoit un rapport de problème, elle peut facilement joindre le fichier journal contenant ces erreurs pour une investigation plus poussée.
Demander de l’aide au département d’Assurance Qualité (QA)
Bien sûr, la méthode la plus efficace pour signaler les problèmes est de demander à l'équipe d'Assurance Qualité de tester le jeu à l'aide du Profiler de Wwise et de joindre le fichier .prof correspondant au rapport de bug. Cette approche exige de l'équipe d'Assurance Qualité qu'elle sache comment utiliser le Profiler Wwise. Le fait d'avoir des collègues dédiés à l'Assurance Qualité qui se concentrent spécifiquement sur les tests de performances audio s'est avéré une ressource inestimable dans notre cas ; il serait donc souhaitable de discuter avec votre direction de la possibilité d'inclure le profiling audio dans la longue liste des responsabilités et tests effectués par le département d'Assurance Qualité.
Optimisation
Dans ce chapitre, nous allons explorer diverses techniques d'optimisation afin d'améliorer les performances de nos assets. Il s'agit notamment d'ajuster différents paramètres sonores, de modifier la façon dont les assets sont joués dans le jeu, et de les organiser efficacement pour économiser des ressources en les chargeant et en les déchargeant lorsque c'est nécessaire.
Travailler directement sur les assets
Lorsque nous considérons la source de nos assets, c'est-à-dire les sons que nous avons créés, nous pouvons appliquer différentes techniques d'optimisation. En fonction de la situation, nous pouvons modifier différentes propriétés de ces sons dans le but de réduire la consommation de ressources tout en maintenant une bonne restitution sonore. L'objectif est de trouver un équilibre où les assets consomment moins de ressources sans compromettre leur qualité.
Lire en stream à partir du disque
Configurer les fichiers pour qu'ils soient lus à partir du disque (stream) est une méthode simple et efficace pour réduire la charge mémoire des fichiers audio. Cette approche convient mieux aux fichiers longs qui ne sont pas critiques en termes de timing (ce qui signifie qu'ils n'ont pas nécessairement besoin d'être parfaitement synchronisés avec l'image), tels que les boucles d'ambiance, la musique ou les dialogues. Les sons courts et ponctuels qui sont étroitement liés à l'image, tels que les coups de feu, les impacts ou les bruits de pas, ne doivent pas être configurés pour une lecture en stream, car leur lecture peut introduire une latence audible en raison du temps nécessaire pour les charger à partir du disque plutôt que de les charger dans la mémoire.
Lorsque l'option « Stream » est activée, aucun média des fichiers lus en stream ne sera inclus dans les SoundBanks. Il est de la responsabilité du Wwise Stream Manager d'ouvrir et de lire ces fichiers directement à partir du disque. Selon les capacités de streaming de la plateforme, il est possible de jouer simultanément une grande quantité de sons en streaming, réduisant ainsi de façon significative la charge mémoire.
Activer le stream pour un son est très simple. Il suffit de cocher la case « Stream » dans l'onglet « General Settings » (paramètres généraux) d'un son ou de son objet parent pour activer l'option de streaming.
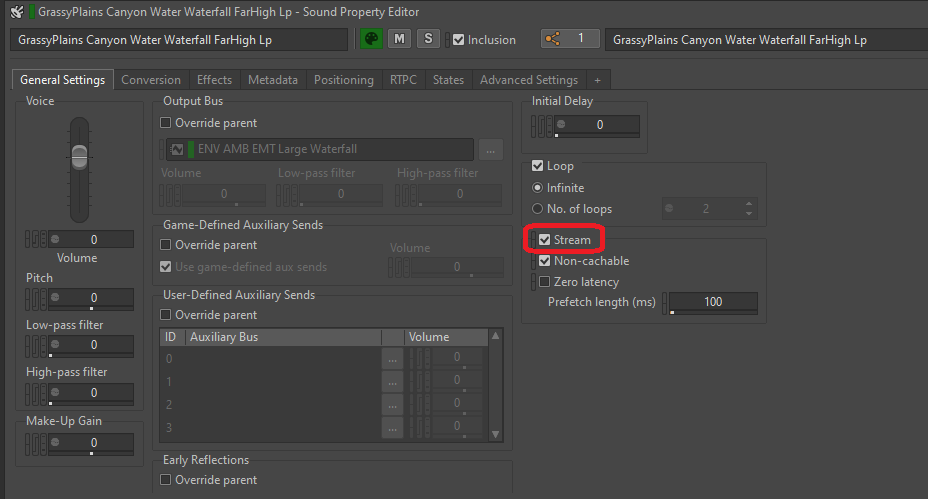
Image 4 : Activation de l'option « Stream » d'un objet SFX
Si nous pensons qu'il est nécessaire qu'un son lu en stream soit parfaitement synchronisé avec l'image, nous pouvons cocher la case « Zero latency » (zéro latence). Cette option permet de charger une petite partie du début du fichier dans la mémoire afin qu'elle soit prête à être jouée sans latence, pendant que le reste du son, lui, est lu en stream. La longueur de la portion préchargée est déterminée par la durée de « Prefetch ».
- Erreurs de défaillances de sources
Comme mentionné ci-dessus, les erreurs de défaillances de sources se produisent lorsque la bande passante du stream atteint sa limite et que le Stream Manager ne peut plus lire les données sur le disque. Cela peut entraîner des coupures sonores et autres erreurs de lecture, il faut donc garder en tête les problèmes potentiels lorsqu'on active l'option Stream.
Raccourcir les sources sonores
Puisque nous parlons des fichiers audio de longue durée, il est possible de modifier les fichiers audio qui occupent beaucoup d'espace, mais dont le contenu est essentiellement similaire pendant toute la durée du son. C'est généralement le cas des sons d'ambiance de base, comme les room tones et les boucles statiques de vent, également connus sous le nom de « beds » (« lits » d'ambiance). Si, pour une raison quelconque, ces boucles ne peuvent pas être lues en stream, le fait de raccourcir leur durée peut réduire considérablement leur utilisation de la mémoire, surtout si vous utilisez un paramètre de conversion qui privilégie la qualité par rapport à la taille du fichier.
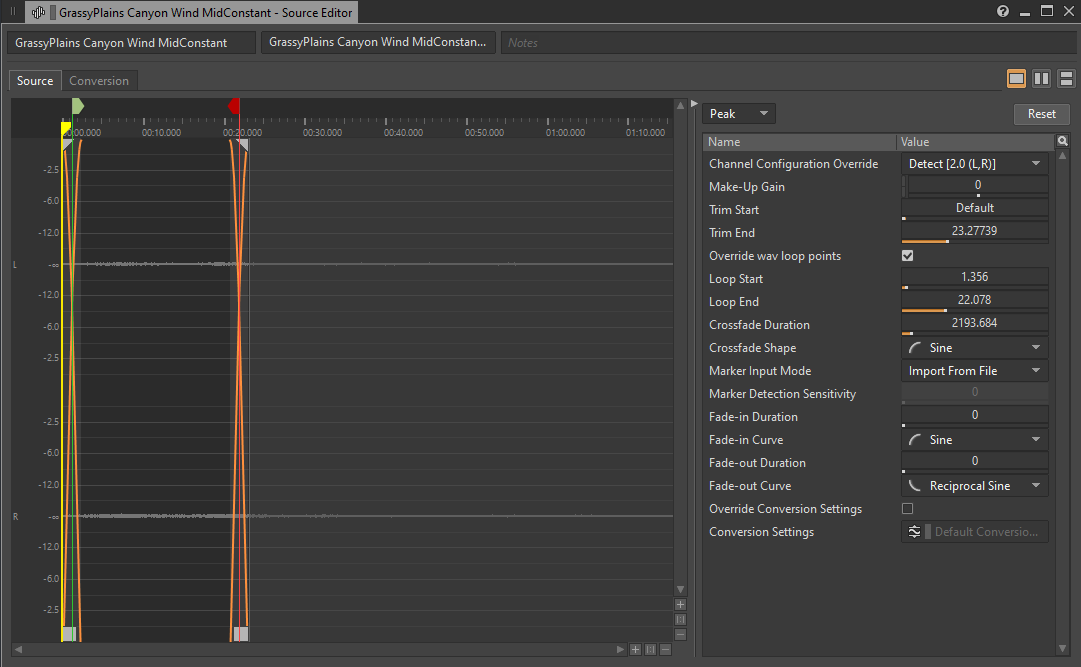
Image 5 : Raccourcissement d'un son d'ambiance
Une approche intéressante pour raccourcir les sons d'ambiance consiste à découper un son en plusieurs courts segments et à les placer dans un Random Container. Le fait de les lire en mode « Continuous » (continu), en « Loop » (boucle) et en « Infinite » (à l'infini) permet d'offrir des variations sur le contenu en lecture tout en utilisant moins de mémoire. Mais gardez à l'esprit que cela peut légèrement augmenter la charge CPU, car le fondu enchaîné entre deux segments génère deux fois plus de voix audio que la lecture d'un seul fichier audio.
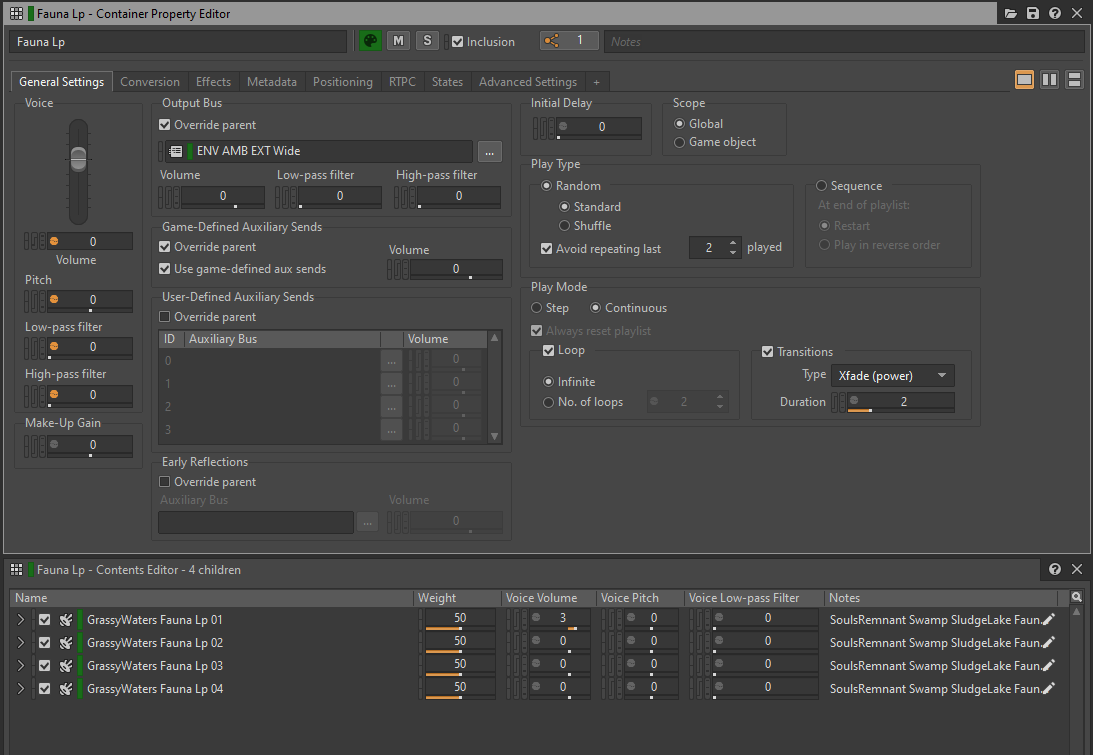
Image 6 : Random Container lu en boucle avec des transitions en fondu enchaîné
Configurer les paramètres de conversion
Lorsque nous appliquons des paramètres de conversion à des fichiers audio, nous décidons du format de fichier final et de la qualité de la conversion pour chaque plateforme. Les formats de fichiers sont déterminés par le codec utilisé pour convertir le fichier .wav original, le nombre de canaux, la fréquence d'échantillonnage et les paramètres de qualité du codec.
Choisir un paramètre de conversion approprié nous permet d'optimiser l'usage mémoire et CPU de notre jeu. Les formats de fichiers sans compression ne sont généralement pas nécessaires pour la version commercialisée du jeu, car les formats compressés comme le Vorbis peuvent fournir d'excellents taux de compression sans perte significative de qualité. Gardez à l'esprit que les fichiers codés doivent être décodés avant d'être lus, et que certains plug-ins qui effectuent le décodage peuvent être plus gourmands en ressources CPU que d'autres.
Comme la plupart des sons utiliseront le même paramètre de conversion, nous pouvons utiliser des ShareSets pour organiser les paramètres de conversion (« Conversion Settings ») en préréglages, ou presets.
Dans notre cas, nous avons trouvé un bon équilibre en utilisant le format Vorbis avec un paramètre de qualité de 4, configuré dans le ShareSet « Default Conversion Settings » (paramètres de conversion par défaut) pour toutes les plateformes. Bien que d'autres codecs comme le WEM Opus ou l'ATRAC9 soient également des options viables qui permettent le décodage matériel sur les plateformes de génération 8, nous étions satisfaits des performances du Vorbis et nous ne voulions pas investir de temps dans leur intégration avec le matériel de génération 8 (l'implémentation Wwise du format Vorbis a été hautement optimisée par Audiokinetic pour toutes les plateformes). De plus, le Vorbis supporte le décodage matériel sur les plateformes de génération 9, ce qui en fait un choix encore plus pratique pour nous.
Le ShareSet « Default Conversion Settings » est défini dans l'onglet « Source Settings » (paramètres des sources) de la fenêtre « Project Settings » (réglages du projet) :
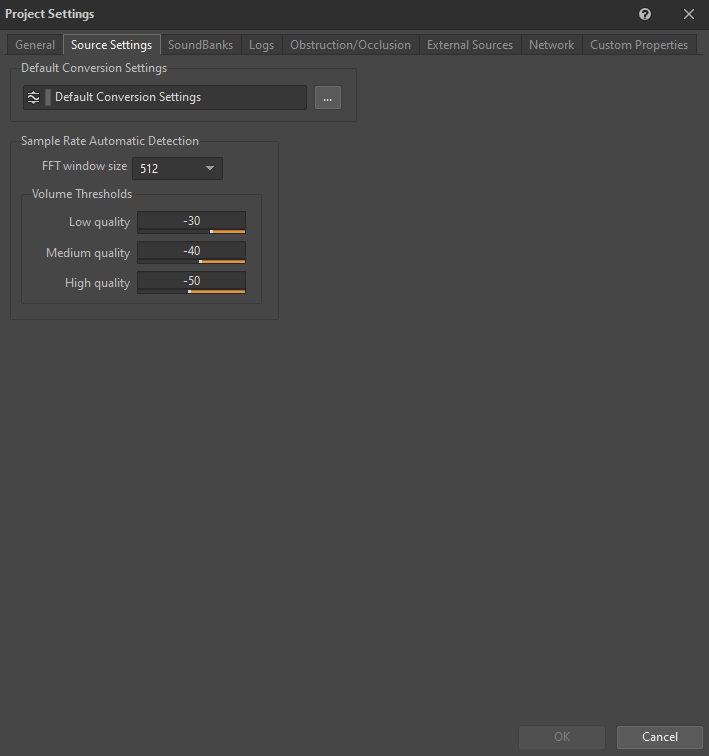
Image 7 : Onglet « Source Settings » de la fenêtre « Project Settings »
Pour vous aider à prendre une décision plus éclairée sur le codec à utiliser, voici un tableau comparant les différents aspects des codecs disponibles supportés par Wwise :
|
Format de fichier |
Ratio de compression |
Usage du CPU |
Usage de la mémoire |
Exemples d'utilisation courante |
Limitations |
|
PCM |
1:1 |
Très faible |
Très faible |
Sons nécessitant une restitution en haute fidélité. |
Aucune. |
|
ADPCM |
4:1 |
Faible |
Modéré |
Sons d'ambiance et SFX. |
Lecture en boucle sur des limites de 64 échantillons seulement. |
|
Vorbis |
3-40:1 |
Modéré à élevé |
Modéré à très faible |
Dialogues, musique, sons d'ambiance et SFX. |
L'overhead des métadonnées est légèrement plus important que pour les autres formats. Il est donc préférable d'éviter ce format pour les sons de très petite taille (moins de quelques dizaines de millisecondes). Nécessite une table de recherche. |
|
AAC |
3-23:1 |
Élevé (faible lors de l'utilisation du décodeur matériel sur iOS) |
Modéré à faible |
Musique d'ambiance (non interactive). |
Overhead de métadonnées très important. Temps de configuration long. Ne convient pas pour une lecture précise à l'échantillon près. |
|
WEM Opus |
10-60:1 |
Élevé (en l'absence d'accélération matérielle), très faible (en cas d'accélération matérielle) |
Modéré à très faible |
Dialogues, musique simple, sons d'ambiance et SFX. |
Les limitations varient en fonction des capacités de la plateforme. |
Tableau 2 : Comparaison de tous les codecs disponibles (d'après la documentation d'Audiokinetic)
- Détection automatique de la fréquence d'échantillonnage
L'option « Sample Rate Automatic Detection » (détection automatique de la fréquence d'échantillonnage) est une option qui permet à l'encodeur de Wwise d'analyser le contenu d'un fichier sonore et de choisir la meilleure fréquence d'échantillonnage pour ce contenu spécifique. Par exemple, si un son est principalement composé de basses fréquences, une fréquence d'échantillonnage plus petite peut être sélectionnée pour réduire la taille du fichier sans perte significative de fidélité audio. Cependant, dans le cas de Scars Above, nous avons décidé de ne pas utiliser cette fonctionnalité. Notre jeu ne comporte pas beaucoup de sons à basses fréquences, et nous voulions nous assurer que tous nos sons avaient la même fréquence d'échantillonnage que la fréquence native de la plateforme, à savoir 48 kHz. Cette approche permet d'éviter les artefacts d'aliasing lors d'un suréchantillonnage vers du 48 kHz. Nous avons également gardé à l'esprit que l'encodeur Vorbis peut entraîner une mauvaise qualité audio lors de la conversion de sons sur une fréquence d'échantillonnage de 16 kHz ou moins, puisque le codec a été spécialement conçu pour des fréquences d'échantillonnage plus élevées.
Convertir en mono
Un bon moyen de réduire la charge mémoire, la taille occupée sur le disque et la charge CPU de notre jeu a été de convertir les sons en mono (le cas échéant) en utilisant un Shareset de Conversion Settings ayant la configuration de canaux réglée sur Mono.
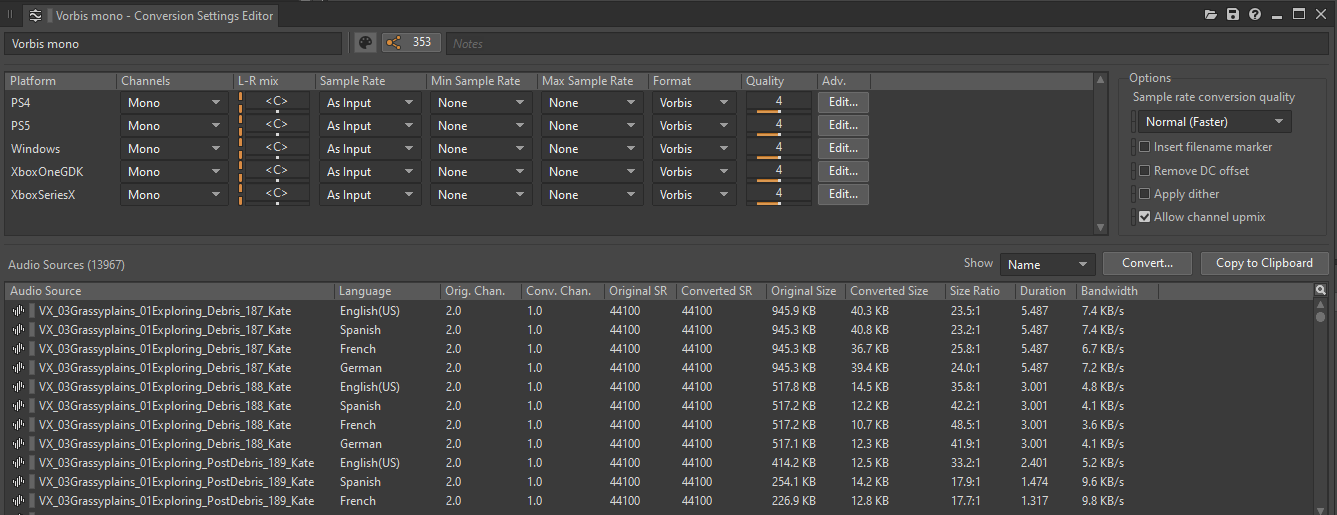
Image 8 : Fenêtre d'édition des Sharesets de paramètres de conversion (Conversion Settings)
Les fichiers multicanaux ont une empreinte mémoire beaucoup plus importante que les fichiers à un seul canal. Par exemple, un fichier stéréo à deux canaux occupera deux fois plus d'espace que son homologue mono.
Plus important encore, nous devons tenir compte de la façon dont les fichiers multicanaux se comportent en tant que sources sonores dans le jeu. Chaque canal audio correspond à une voix audio dans le jeu. Cette règle s'applique également aux objets audio, ce qui signifie que chaque canal correspond à un objet audio. Lors de l'insertion de plug-ins dans des sons multicanaux, chaque canal créera une instance du plug-in. Cet effet se propage à tous les enfants de la hiérarchie, à moins que l'option ne soit explicitement désactivée sur ceux-ci.
Il est facile de voir comment des fichiers audio comportant de nombreux canaux peuvent faire augmenter les coûts en ressources. Plus de voix ou d'objets audio nécessitent d'allouer plus de ressources CPU pour les plug-ins, la conversion et le mixage de ces sons.
Envisagez de convertir en mono les sons qui répondent à un ou plusieurs des critères suivants :
- Le contenu de tous les canaux est identique ou très similaire ;
- Le son utilise un preset d'atténuation ayant une distance d'atténuation très faible ;
- Le son utilise un preset d'atténuation ayant une valeur de Spread très faible.
Les sons qui se prêtent généralement bien à une conversion en mono sont les dialogues, les sons émis par des émetteurs de petite taille dans un niveau (comme des petits ennemis ou des petites bêtes), certains sons de l'interface utilisateur, les sons de Foley (en fonction de leur taille et de leur distance), les petites interactions dans un niveau, etc.
Pour convertir un fichier en mono, vous pouvez remplacer le preset par défaut « Default Conversion Settings » par un autre ShareSet approprié depuis l'onglet « Conversion » d'un son ou de son objet parent, en cochant l'option « Override parent », et en sélectionnant le Shareset.
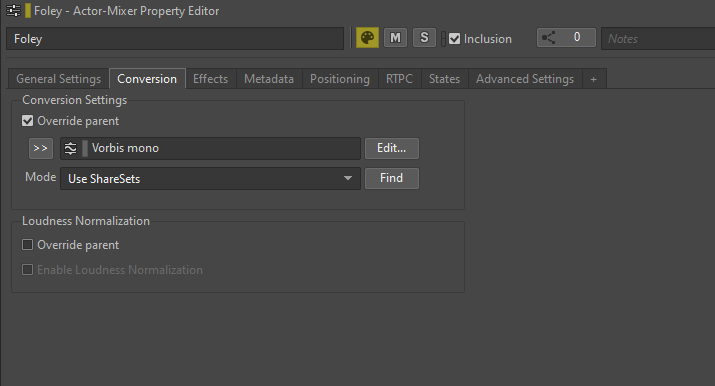
Image 9 : Remplacement d'un preset de Conversion Settings
Pour avoir une vue d'ensemble de tous les objets configurés pour être convertis en mono, vous pouvez consulter la liste des références du ShareSet de Conversion Settings utilisé :
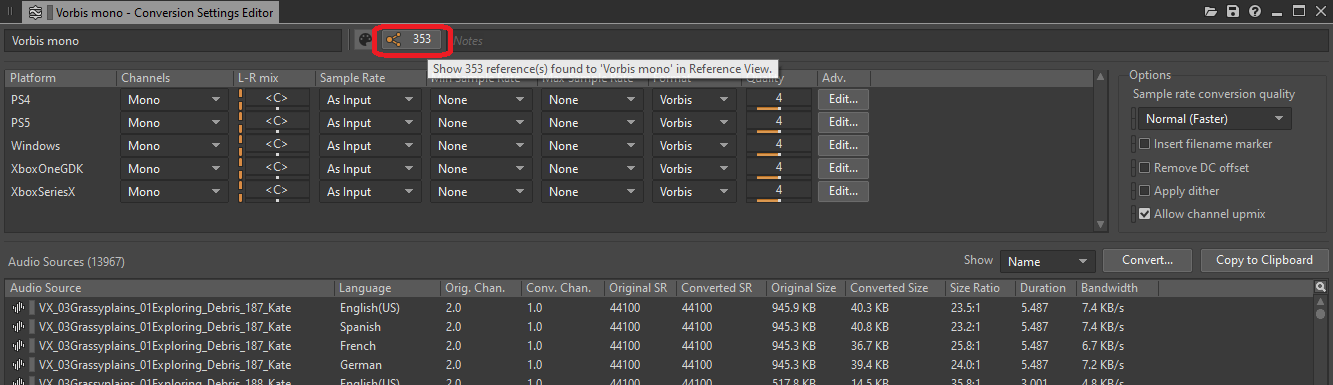
Image 10 : Bouton d'affichage des références dans la fenêtre d'édition des Conversion Settings
Cliquer sur le bouton ouvre une fenêtre « Reference View » (vue des références) répertoriant toutes les références à ce ShareSet :
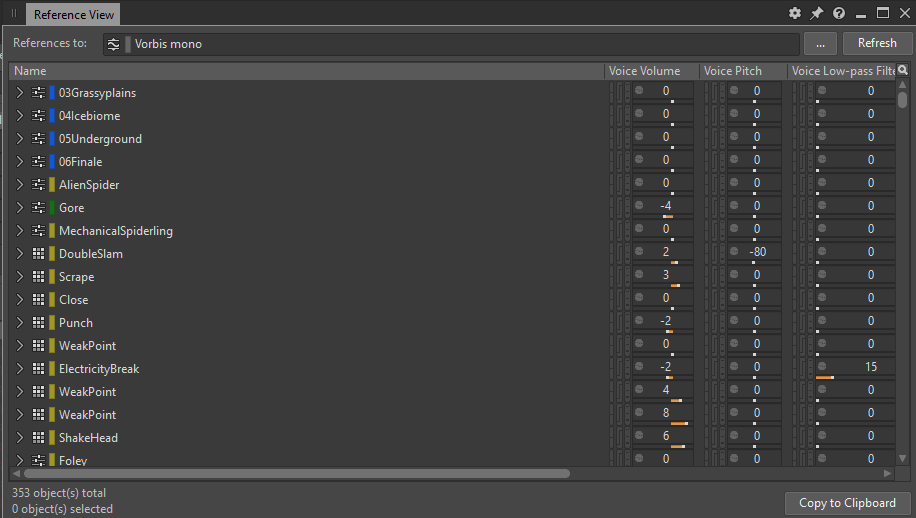
Image 11 : Fenêtre « Reference View » affichant toutes les références au preset « Vorbis mono ».
Consolider les Blend Containers
Une pratique d'optimisation que nous avons adoptée dans notre projet Wwise a été de consolider (ou enregistrer) tous les Blend Containers. Nous appelons par le terme « consolider » le fait d'enregistrer la sortie d'une source, dans ce cas un Blend Container, dans un nouveau fichier audio, et de remplacer la source par le nouveau fichier. À l'issue de ce processus, tous les Blend Containers sont remplacés par des objets SFX uniques.
Pendant la phase de production de notre jeu, nous avons importé de nombreux sons, et les Blend Containers nous ont fourni un moyen pratique d'organiser plusieurs couches sonores dans un seul Container. Cela nous a permis de tester facilement le Container en le déclenchant avec une seule action Play depuis un Event. Le fait d'avoir des couches sonores séparées dans Wwise nous a permis d'améliorer le mixages de ces différentes textures, tandis que le fait de les avoir toutes sous un seul objet parent nous a donné la possibilité de les déclencher et de les traiter de différentes manières.
Cependant, utiliser les Blend Containers uniquement pour organiser des couches sonores peut sembler exagéré. L'objectif principal des Blend Containers est de créer des Blend Tracks, qui nous permettent de définir des transitions précises entre les objets enfants du Container et de contrôler ces transitions à l'aide de différents paramètres de jeu.
Comme chaque Blend Container, lorsqu'il est déclenché, a plusieurs objets enfants qui jouent tous en même temps, nous devons être conscients de la charge CPU associée aux Blend Containers. Par exemple, si nous avons un Blend Container « Gunshot » (coups de feu) avec des Containers enfants distincts pour les couches « Impact », « Tail » (queue du son), « Foley » et « Mechanics » (mécaniques), le déclenchement du Blend Container jouera les quatre sons en même temps.
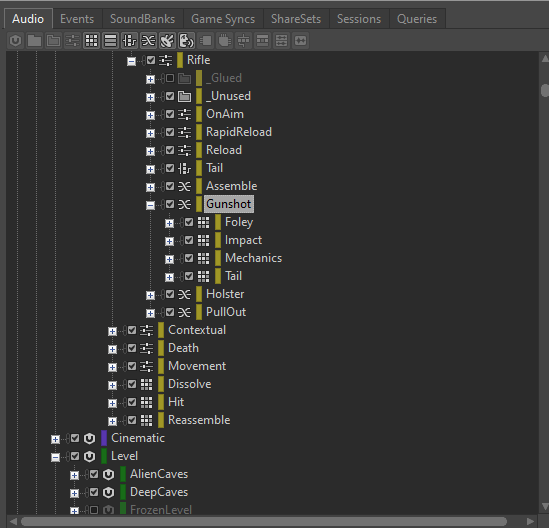
Image 12 : Exemple d'un Blend Container avec quatre Random Containers enfants
En supposant que chaque couche de l'Event « Gunshot » soit configurée pour une lecture stéréo sur deux canaux, le déclenchement de cet Event occuperait huit voix audio physiques. Si plusieurs Events « Gunshot » sont déclenchés rapidement, le nombre de voix peut rapidement augmenter. En outre, si des plug-ins sont insérés sur le Blend Container, chaque Event « Gunshot » génèrera huit instances de chaque plug-in inséré.
Consolider ce Blend Container réduirait le nombre de voix utilisées de huit à deux, ce qui entraînerait une réduction significative de la charge mémoire et CPU.
Si les Containers enfants du Blend Container sont des Random Containers, configurés pour générer différentes superpositions de couches sonores à chaque déclenchement de l'Event « Gunshot », nous pouvons consolider le même Blend Container autant de fois que nécessaire, créant ainsi suffisamment de variations tout en conservant une bonne fidélité audio et en obtenant un son de coup de feu optimisé.
La meilleure façon de consolider un Blend Container est d'en enregistrer la sortie depuis l'outil de création Wwise lui-même. En insérant un plug-in Wwise Recorder sur le Master Audio Bus et en le configurant de manière appropriée, chaque déclenchement du Blend Container peut être enregistré sur le disque en un fichier .wav distinct.
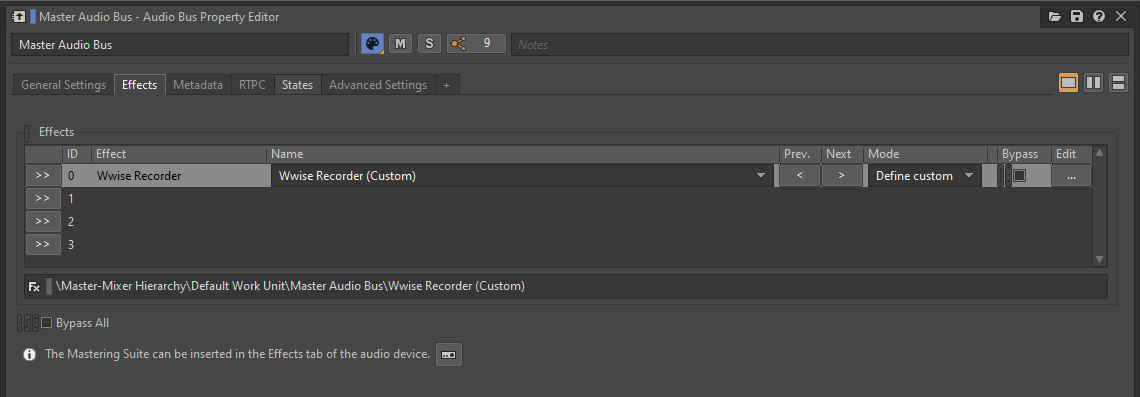
Image 13 : Plug-in Wwise Recorder inséré sur le Master Audio Bus
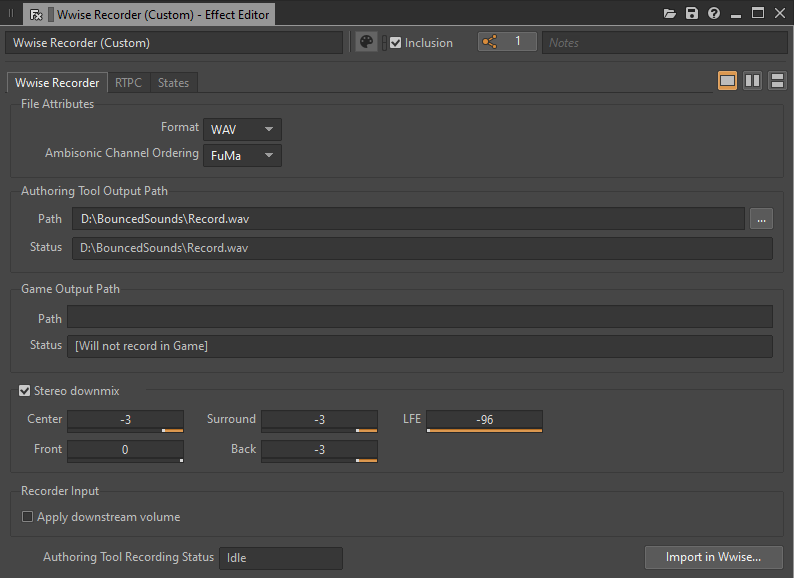
Image 14 : Fenêtre de l'éditeur d'effet du Wwise Recorder
Une fois que le Blend Container a fini de jouer, le fichier .wav correspondant est créé. Il est important de déplacer le fichier enregistré à un autre endroit ou de lui attribuer un nom approprié avant de procéder à l’enregistrement d’une nouvelle prise. Cela permet de s'assurer que chaque lecture n'écrase pas l'enregistrement précédent.
Après avoir généré un nombre suffisant de variations, tous les fichiers enregistrés peuvent être importés dans un Random Container nouvellement créé. Ce Random Container peut alors être utilisé pour remplacer le Blend Container déclenché dans l'Event. N'oubliez pas de retirer ou de désactiver le plug-in Wwise Recorder du Master Audio Bus une fois les enregistrements effectués.
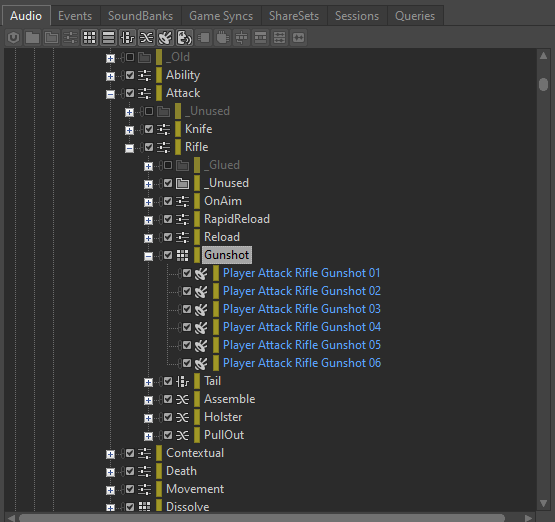
Image 15 : Random Container avec les variations générées par la plug-in Wwise Recorder
J'ai trouvé utile de conserver dans le projet le Blend Container inutilisé, au cas où il serait nécessaire de modifier le son consolidé et de pouvoir refaire le processus d'enregistrement dans le futur. Je suggère de le placer dans un dossier « _Glued » et de l'exclure. De cette façon, si nous voulons générer de nouvelles variations, nous pouvons facilement l'inclure à nouveau, réinsérer le plug-in Wwise Recorder, faire les changements nécessaires et enregistrer de nouvelles prises.
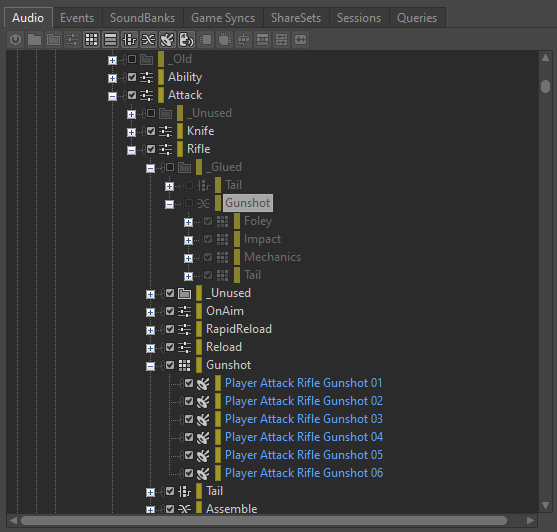
Image 16 : Blend Container exclu
Optimiser le traitement des effets
Le traitement des sons dans Wwise à l'aide des plug-ins d'effets fournis peut prendre beaucoup de ressources CPU, et même de mémoire. Cependant, il existe plusieurs méthodes pour optimiser les traitements audio et améliorer les performances dans l'environnement Wwise. Dans les sections suivantes, nous allons explorer ces méthodes d'optimisation en détail.
- Rendre les effets
Tel que mentionné précédemment, chaque effet ajouté à un objet audio dans Wwise créera une instance pour chaque canal de l'objet et de ses objets enfants. Le traitement effectué par ces plug-ins est calculé en temps réel durant l'exécution du jeu. Cependant, si nous avons des effets de traitement qui n'ont pas besoin d'être modifiés dynamiquement par un paramètre de jeu, nous pouvons plutôt choisir de les rendre.
L'activation de l'option de rendu « Render » permet d'intégrer l'effet au son avant son packaging dans une SoundBank. Cette approche permet d'économiser des ressources CPU pendant l'exécution du jeu. Mais, comme indiqué précédemment, il sera impossible d'utiliser des paramètres de jeu (RTPC) pour modifier ou désactiver l'effet une fois qu'il aura été rendu.
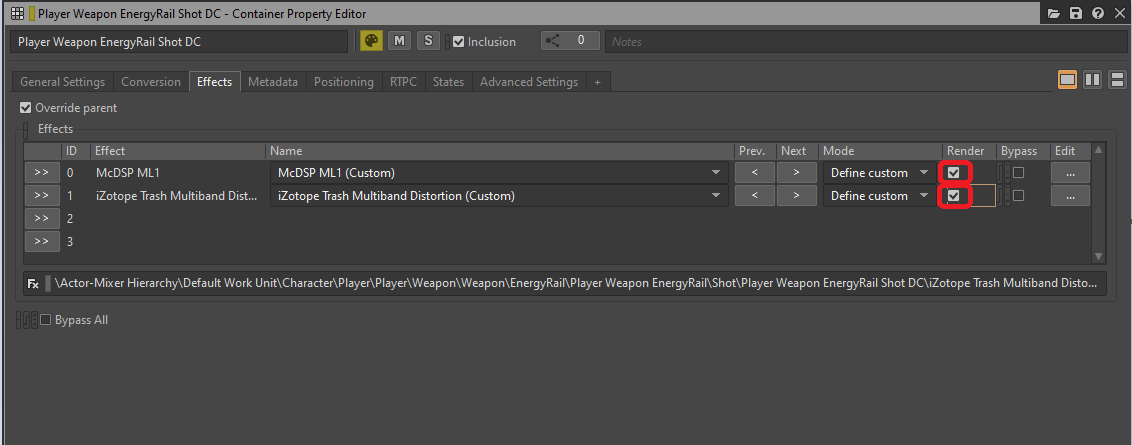
Image 17 : Sélection de l'option Render dans l'onglet Effects depuis la fenêtre Property Editor
Il existe un moyen simple d'obtenir une liste de tous les effets insérés sur des objets et pouvant être rendus. Si nous générons un rapport d'intégrité « Integrity Report » (le raccourci par défaut vers sa fenêtre est [Shift + G]), toutes les instances d'effets qui peuvent être optimisés à l'aide de l'option de rendu seront répertoriées pour chaque plateforme, avec le message suivant :
« The effect could be rendered to save CPU, since no parameter will change in game » (L'effet pourrait être rendu pour économiser du CPU, puisqu'aucun de ses paramètres ne change en cours de jeu).
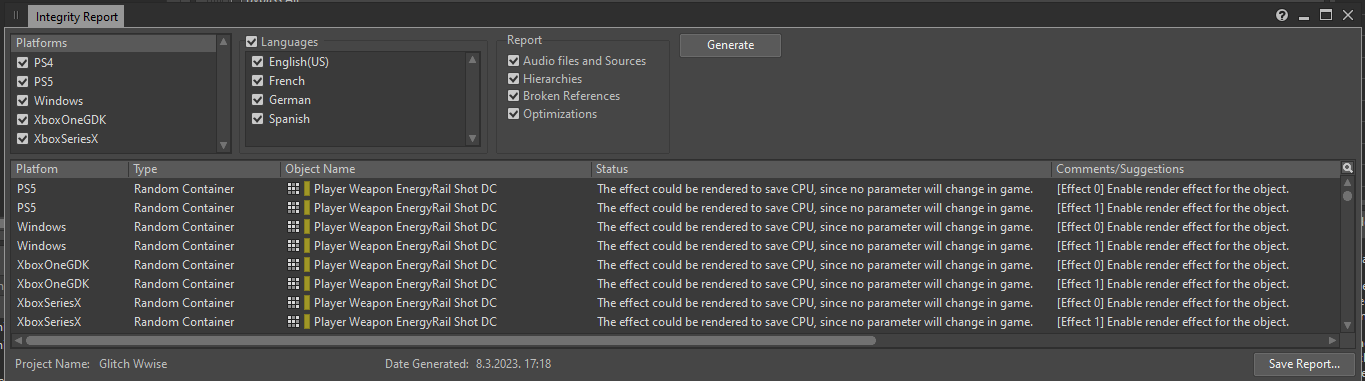
Image 18 : Fenêtre du rapport d'intégrité (Integrity Report)
À partir de là, vous pouvez ouvrir la fenêtre Property Editor d'un objet contenant l'effet et activer l'option « Render ». Une fois cette opération effectuée, ces effets ne devraient plus figurer dans le rapport d'intégrité (pour ces problèmes spécifiques liés au rendu).
- Insertion d'effets au niveau des bus
En général, une bonne habitude à avoir lorsqu'on utilise des effets qui ne peuvent pas être rendus est de les insérer dans les bus audio plutôt que dans les objets situés dans l'Actor-Mixer Hierarchy ou l'Interactive Music Hierarchy. En effet, les bus ont un nombre fixe de canaux et l'insertion d'un effet dans un bus instanciera l'effet autant de fois qu'il y a de canaux dans le bus. En revanche, l'insertion d'un effet dans un objet situé dans l'Actor-Mixer Hierarchy instanciera l'effet pour chaque canal de chaque enfant de cet objet. Les deux approches devraient finalement produire le même son, mais la première créera moins d'instances de l'effet.
Il existe toutefois une exception à cette règle, lorsque le bus possède plus de canaux que les objets qui lui sont envoyés. Dans ce cas, le bus créera des instances supplémentaires de l'effet par rapport aux objets SFX, et il peut donc être préférable d'insérer l'effet dans l'objet SFX. Il existe également des exceptions à cette règle - les réverbérations ont un coût de performance négligeable par canal et sont souvent mieux utilisées sur les bus auxiliaires.
- Appliquer les traitements audio par des effets plutôt que dans l'onglet « General Settings »
Pour économiser encore plus de ressources, nous pouvons prendre en considération certains paramètres d'un bus ou d'un objet agissant comme des effets, et qui consomment de la puissance de traitement pendant l'exécution du jeu. Les paramètres tels que le Bus Volume ou le Voice Volume, le Pitch, le filtre Low-pass (passe-bas) ou High-pass (passe-haut), présents dans l'onglet « General Settings » (paramètres généraux), consomment toujours des ressources CPU pendant l'exécution du jeu et, s'ils ne sont pas modifiés par un paramètre de jeu, peuvent être remplacés par des plug-ins d'effets dédiés, puis rendus.
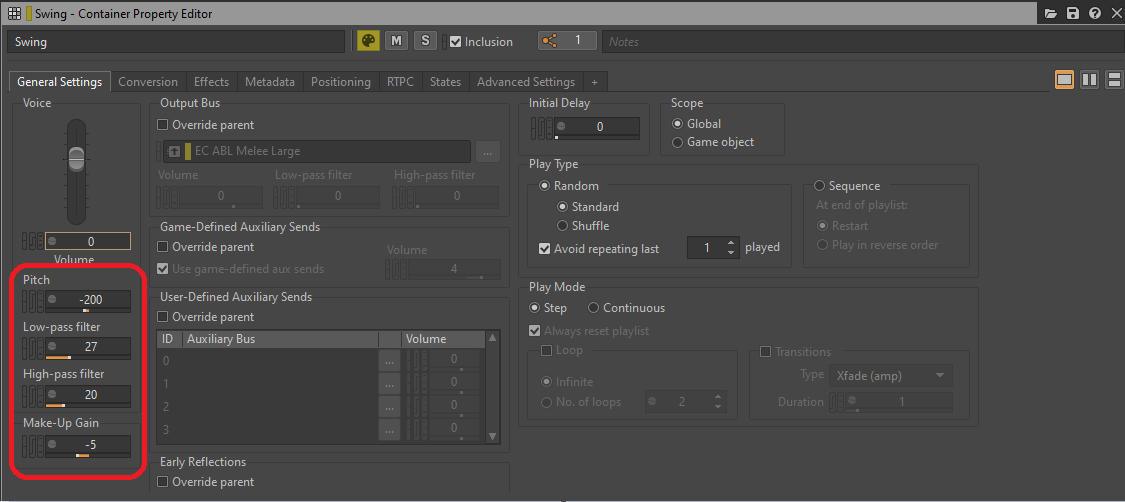
Image 19 : Paramètres de traitement de l'onglet « General Settings »
Le filtre passe-bas et le filtre passe-haut peuvent être remplacés par une instance du plug-in Wwise Parametric EQ (égaliseur paramétrique), tandis que le Pitch peut être remplacé par une instance du plug-in Wwise Pitch Shifter ou Wwise Time Stretch. Les réglages de volume ou de Make-Up Gain peuvent être remplacés par un plug-in Wwise Gain.
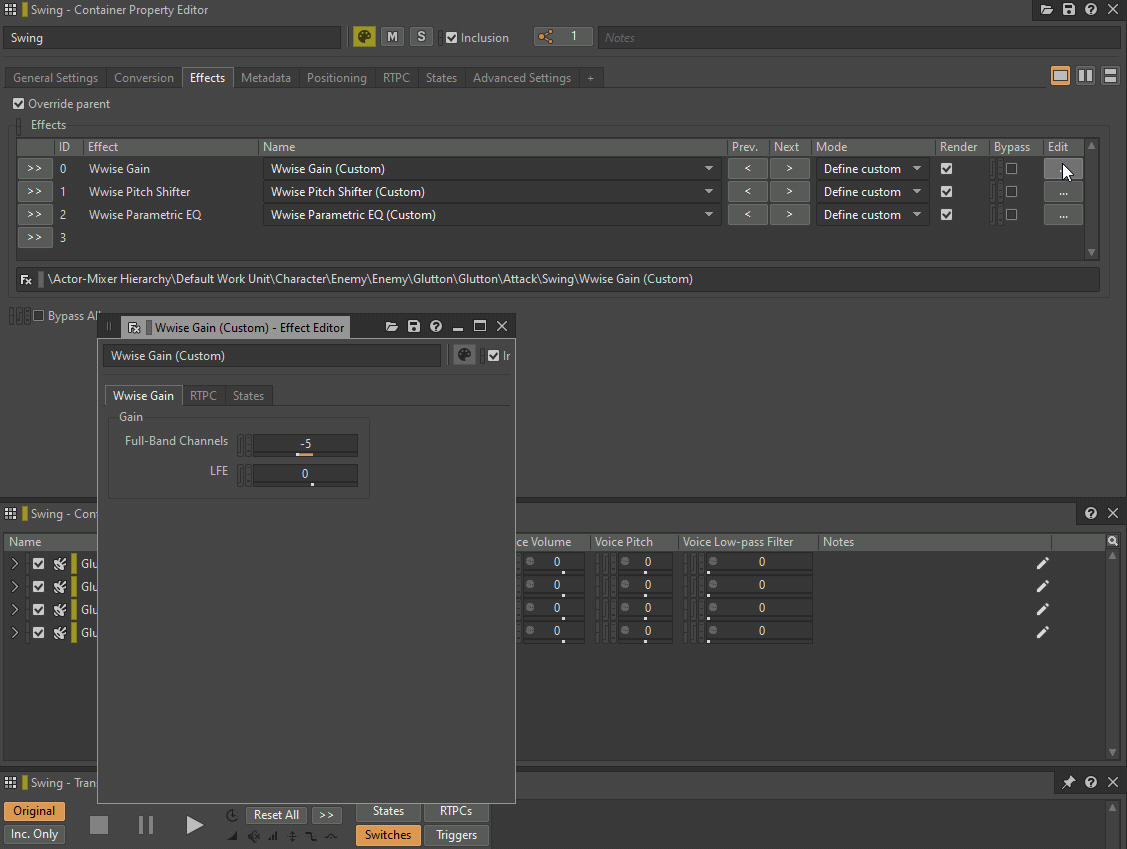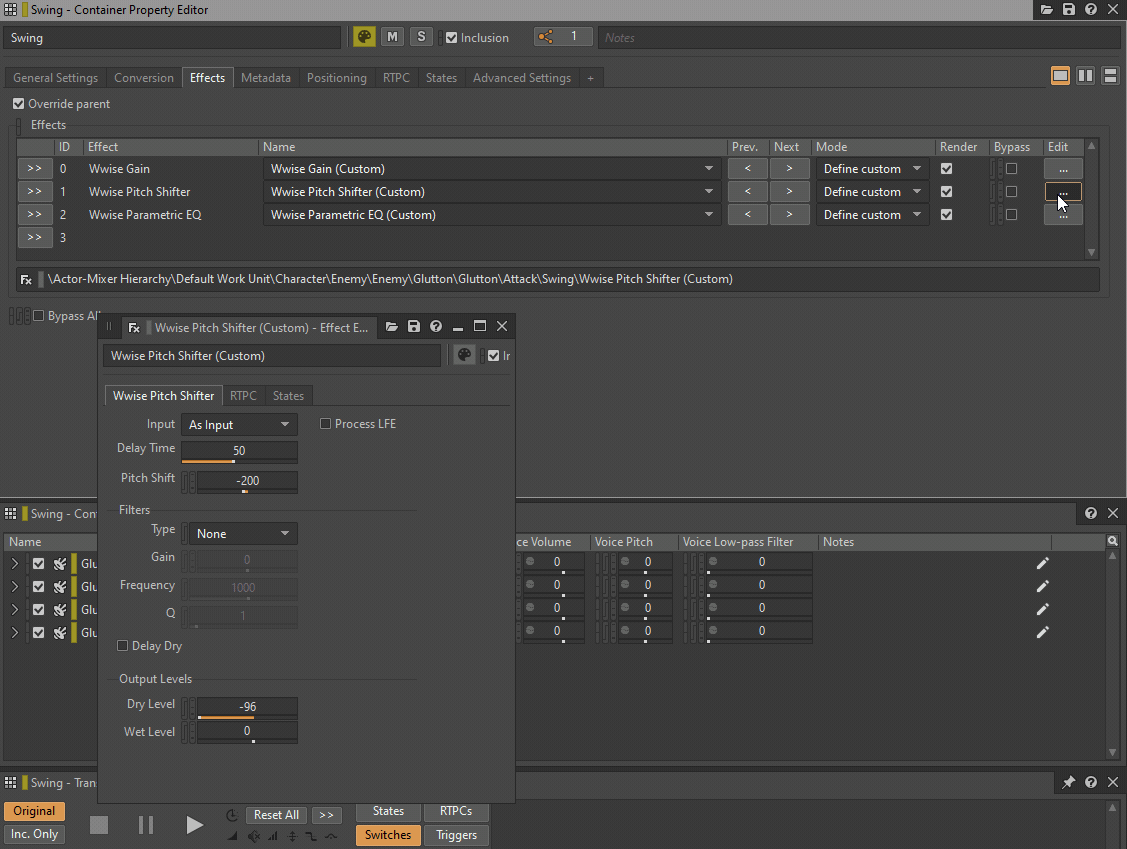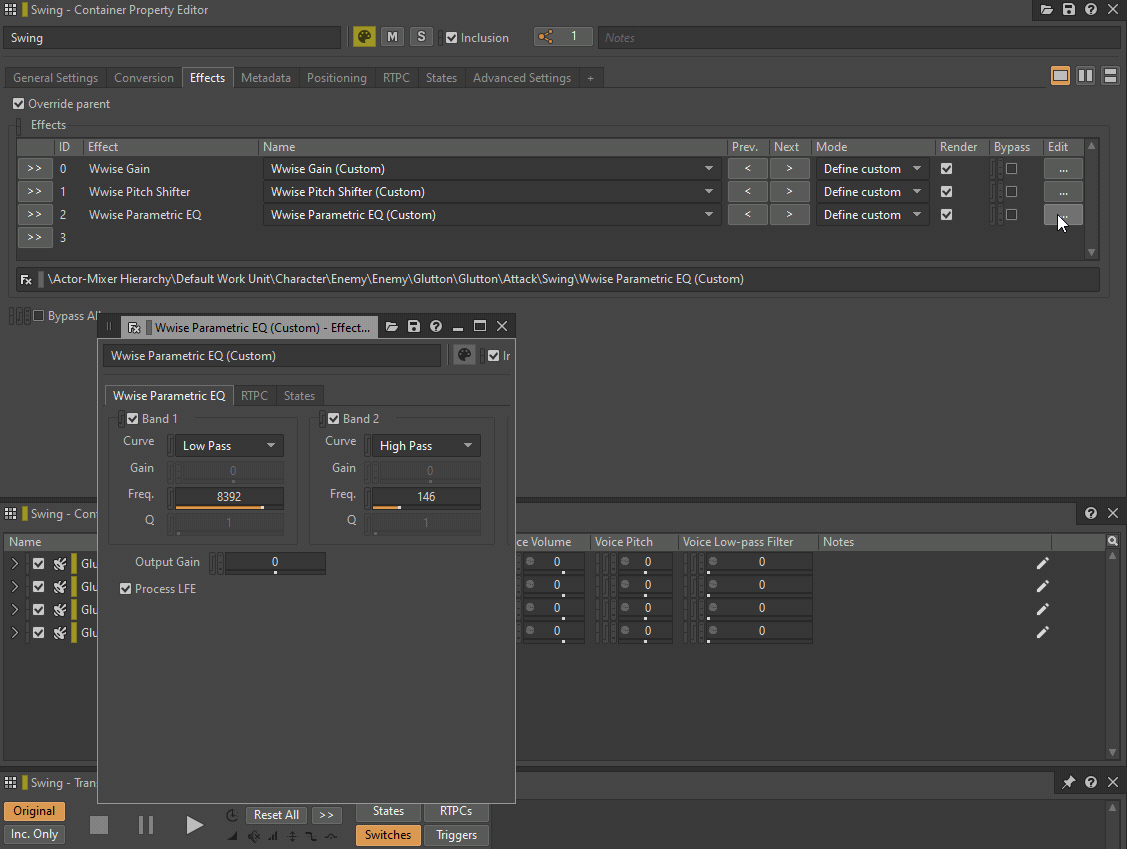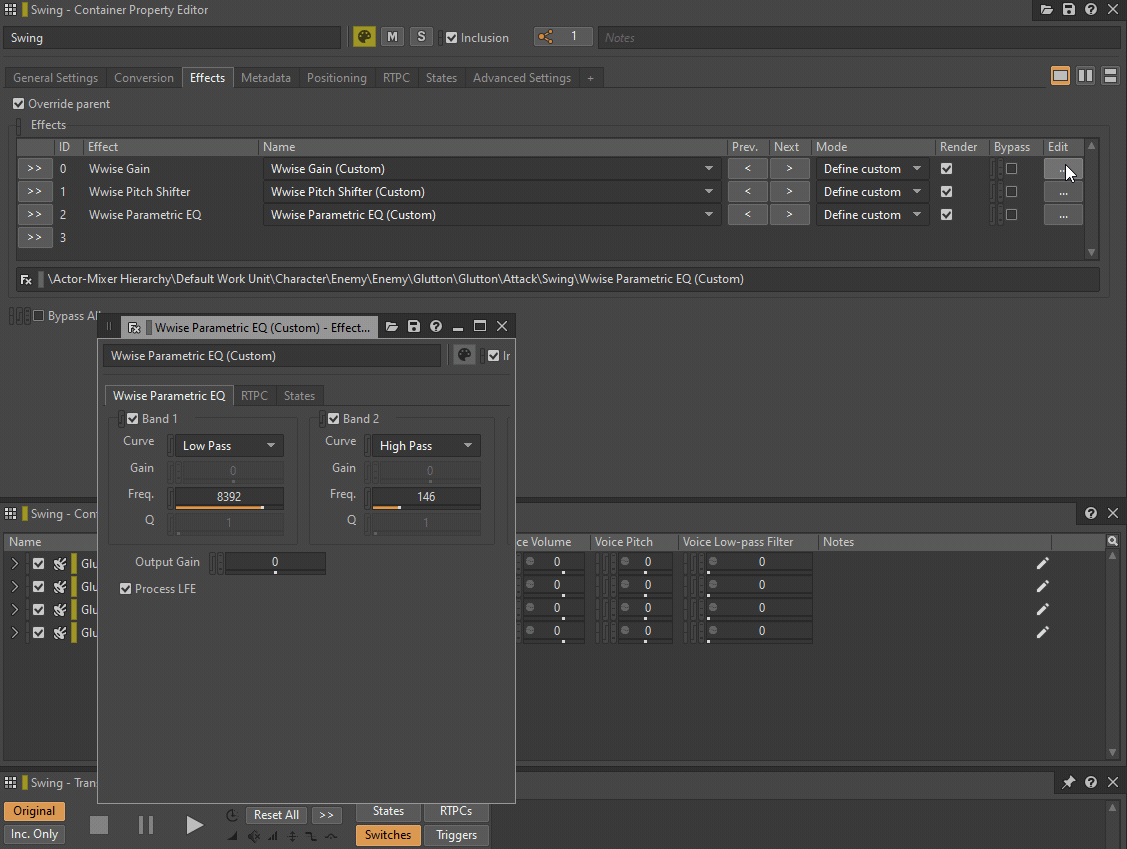
GIF 1 : Plug-ins Wwise insérés à la place des paramètres situés dans l'onglet General Settings
Voici un lien vers un tableau tiré de la documentation d'Audiokinetic référençant les valeurs des filtres LPF (filtre passe-bas) et HPF (filtre passe-haut) à leurs fréquences de coupure :
Fréquences de coupure des valeurs LPF et HPF de Wwise
Optimiser la lecture des assets
Dans cette section, je vais expliquer comment les assets sonores sont joués et arrêtés, les concepts de voix audio et d'AkComponents, et les étapes que nous pouvons suivre pour optimiser la lecture et le déclenchement des sons.
Voix audio
Chaque son discret joué dans le jeu occupe une voix audio. Lorsqu'un Event est déclenché, une source audio associée à cet Event devient une « Voice » (voix) pendant l'exécution du jeu. Ces voix nécessitent des calculs pour leur permettre d'être générées et pour appliquer divers comportements. Ces calculs dépendent principalement de la quantité de traitement effectuée sur cette voix. En minimisant les calculs et en ne les exécutant que lorsque cela est nécessaire, nous pouvons économiser des ressources CPU considérables.
Pour afficher une liste de toutes les voix jouant actuellement dans le jeu, vous pouvez vous connecter au jeu dans le Profiler Wwise et sélectionner l'onglet « Voices » :
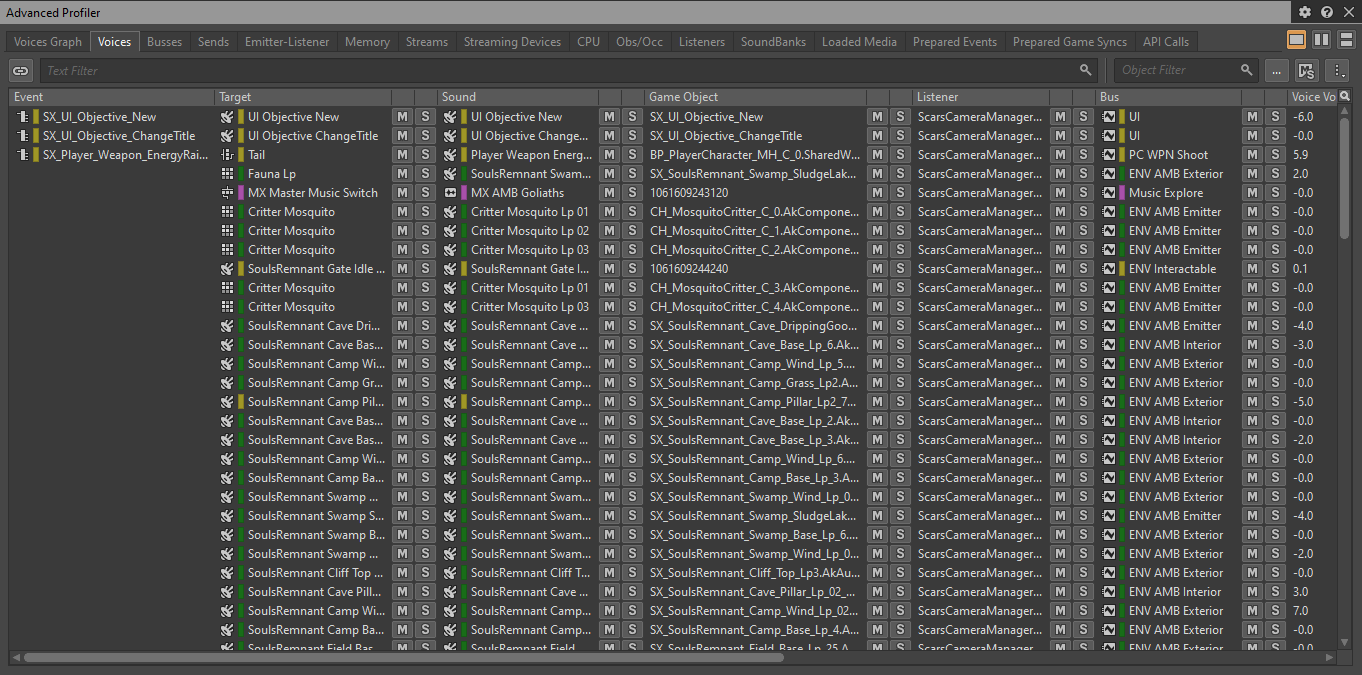
Image 20 : Onglet « Voices » de la fenêtre « Advanced Profiler »
- Voix virtuelles
Lorsqu'une voix est active et produit un son, elle est appelée « Physical Voice » (voix physique). Chaque voix physique subit les calculs suivants à chaque image :
- Décodage du fichier audio ;
- Rééchantillonnage du son (en appliquant également le changement de Pitch si utilisé) ;
- Traitement des effets et des filtres ;
- Calcul du Volume.
Lorsqu'une voix physique n'est pas audible, par exemple lorsque son objet Actor associé est trop éloigné, elle peut être définie comme « Virtual Voice » (voix virtuelle). Les voix virtuelles ignorent tous les calculs, à l'exception du calcul du Volume, qui est nécessaire pour déterminer à quel volume le son doit être joué lorsqu'il redevient audible. Le fait de remplacer les voix physiques par des voix virtuelles permet d'économiser beaucoup de ressources CPU, et s'assurer qu'aucun son inaudible ne reste actif a constitué une étape importante dans l'optimisation de notre jeu.
Le comportement des voix virtuelles peut être défini pour chaque asset audio dans l'onglet « Advanced Settings » (paramètres avancés) de la fenêtre « Property Editor » :
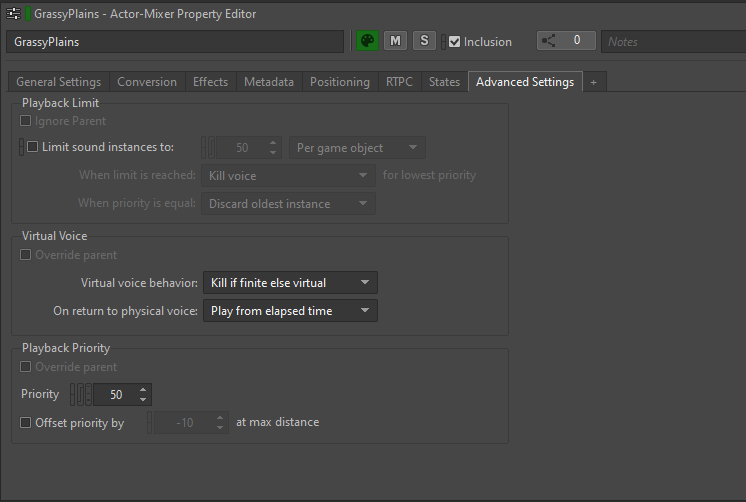
Image 21 : Onglet « Advanced Settings » de la fenêtre « Property Editor »
Les options de comportement (« behavior ») des voix virtuelles déterminent ce qu'il advient d'une voix lorsque son volume tombe en dessous du paramètre de Volume Threshold (seuil de volume audible).
Plusieurs options sont disponibles :
- Continue to play (continuer à jouer) : La voix reste active et continue de jouer normalement ;
- Kill voice (couper la voix) : La voix est complètement arrêtée et n'est plus jouée ;
- Send to virtual voice (envoyer à une voix virtuelle) : La voix devient une voix virtuelle, ce qui permet d'ignorer la plupart des calculs, à l'exception du calcul du volume ;
- Kill if finite else virtual (couper si la voix est finie, sinon envoyer à une voix virtuelle) : Si le son est délimité dans le temps (et non lu en boucle), il est complètement arrêté lorsqu'il devrait être envoyé à une voix virtuelle. Si le son est lu en boucle, il devient une voix virtuelle.
Nous avons généralement l'habitude de définir la valeur par défaut sur « Kill if finite else virtual » pour la plupart des assets. Cela couvre presque tous les cas où le son doit être traité lorsque son volume tombe en dessous d'un certain seuil. Les sons délimités dans le temps sont coupés car nous n'entendrons pas le reste du son si nous nous éloignons, tandis que les sons lus en boucle sont envoyés à une voix virtuelle.
Lors du retour à l'état de voix physique, nous avons choisi de régler toutes les voix virtuelles sur « Play from elapsed time » (jouer à partir du temps écoulé). Cela signifie qu'en plus du calcul du volume, Wwise garde en mémoire le temps pendant lequel la voix a été dans un état virtuel. Lorsque la voix redevient active, elle continue de jouer à partir du temps écoulé, ce qui permet de conserver une perception homogène de l'écoulement du temps dans le jeu.
- Seuil de volume (Volume Threshold) et nombre maximal de voix (Max Voice Instances)
Afin que Wwise puisse déterminer à quel moment envoyer une voix physique dans une voix virtuelle, nous devons spécifier le seuil de volume audible, ou « Volume Threshold ». Le seuil de volume audible représente le niveau de volume minimum en dessous duquel les sons sont considérés comme suffisamment faibles pour être convertis en voix virtuelles en toute sécurité.
Il est défini pour chaque plateforme dans l'onglet « General » des paramètres du projet (« Project Settings ») :
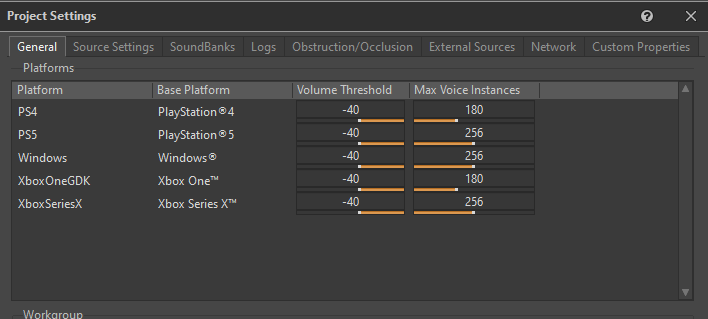
Image 22 : Onglet « General » de la fenêtre « Project Settings »
Nous avons déterminé qu'un seuil de volume de -40 était approprié pour le comportement des voix virtuelles.
Le paramètre « Max Voice Instances » (nombre maximal de voix) définit le nombre maximal de voix physiques autorisées par plateforme. Si le nombre de voix physiques dépasse cette limite, toutes les voix supplémentaires seront immédiatement envoyées en fonction de leurs priorités vers des voix virtuelles. Nous avons fixé des valeurs relativement élevées pour ce paramètre, car nous voulions avoir un meilleur contrôle sur le nombre de voix dans le jeu.
Lors du profiling des voix, il est important de surveiller deux paramètres : « Number of Voices (Physical) » (nombre de voix physiques) et « Number of Voices (Total) » (nombre total de voix). La donnée « Number of Voices (Physical) » indique le nombre de voix physiques simultanées jouant activement dans le jeu, tandis que la donnée « Number of Voices (Total) » indique le nombre combiné de voix physiques et de voix virtuelles chargées.
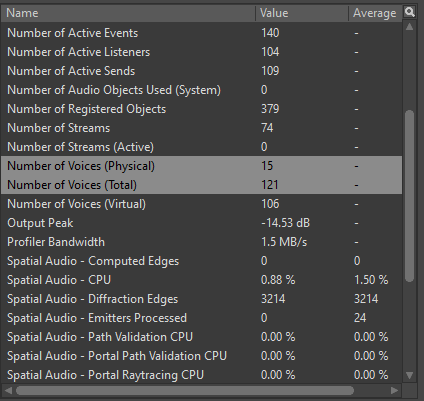
Image 23 : Paramètres « Number of Voices » du Profiler de Wwise
Nous avons établi une règle générale pour chaque plateforme concernant le nombre maximum de voix physiques et totales autorisées, comme indiqué dans le tableau ci-dessous :
|
|
Voix physiques (Max) |
Voix totales (Max) |
|
Génération 8 |
30 |
500 |
|
Génération 9 |
40 |
600 |
|
PC |
40 |
600 |
Tableau 3 : Nombre maximal de voix par plateforme
Même si les voix virtuelles sont beaucoup moins gourmandes en ressources de calculs que les voix physiques, il est important d'en éviter une utilisation excessive dans le jeu. Bien que moins gourmandes en ressources, les voix virtuelles nécessitent toujours des calculs de volume et de temps écoulé. Plus important encore, les voix virtuelles sont toujours considérées comme des émetteurs et, si elles sont envoyées à Spatial Audio, elles contribueront aux calculs des chemins de diffraction.
- Limite de lecture (Playback Limiting)
Dans les situations où un son peut potentiellement être déclenché un nombre imprévisible de fois ou lorsqu'il y a un nombre excessif d'instances du même son jouant simultanément, il est possible d'appliquer dans Wwise une limite de lecture à ce son.
L'option « Playback Limit » (limite de lecture) se trouve dans l'onglet « Advanced Settings » du Property Editor, où il est possible de définir l'option « Limit sound instances to » (limiter les instances du son) sur un nombre prédéfini. Nous avons la flexibilité de choisir le mode d'application de la limite. Choisir entre « Game Object » (objet de jeu) et « Global » nous permet de limiter le son à chaque objet Actor ou à l'ensemble du jeu.
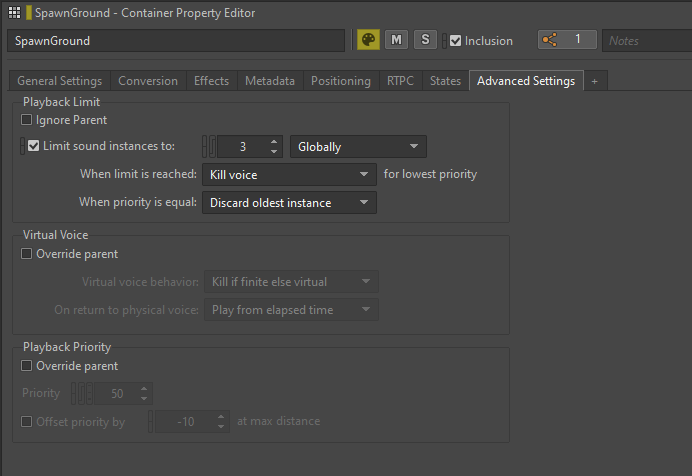
Image 24 : Limitation des instances sonores d'un Random Container
Nous avons principalement utilisé la limite d'instances sonores pour les sons des ennemis, en particulier lors de scénarios de combat intenses où l'apparition de plusieurs ennemis du même type pouvait déclencher de nombreux sons similaires en même temps. En appliquant des limites de lecture, nous avons non seulement optimisé les performances de notre jeu, mais aussi amélioré le mixage général en réduisant les chevauchements sonores excessifs.
AkComponents
Un AkComponent sert de représentation d'un Event Wwise actif dans Unreal Engine et est dérivé du USceneComponent.
Du point de vue d'un concepteur sonore, nous pouvons considérer les AkComponents comme des sources sonores ou comme des haut-parleurs dans le jeu. Lorsqu'ils sont présents dans le jeu, ces haut-parleurs peuvent émettre des sons, être attachés à des Actors et même se déplacer avec eux.
La bonne gestion des AkComponents de notre jeu a été une étape cruciale dans l'optimisation des performances audio. Chaque AkComponent actif exige que divers calculs soient effectués à chaque image, ce qui fait qu'un nombre excessif d'AkComponents enregistrés nécessite énormément de ressources CPU.
Pour optimiser la lecture des sons, nous devrions utiliser les AkComponents déjà existants autant que possible au lieu d'en créer de nouveaux pour chaque Event. En gardant une trace de tous les AkComponents existant dans le jeu et en jouant les sons dessus lorsque cela est nécessaire, nous pouvons réduire l'usage global du CPU.
Les candidats idéaux sur lesquels placer des AkComponents sont les Actors qui sont constamment présents et en mouvement dans le jeu, comme le personnage du joueur, les PNJ, les ennemis, les projectiles, et ainsi de suite. Certains Actors, comme les AkAmbientSounds, peuvent déjà avoir un AkComponent assigné par défaut.
- Utiliser « Post Event at Location » à la place d'un AkComponent
La fonctionnalité « Post Event at Location » (déclencher un Event à un emplacement) de Wwise permet de déclencher des Events sans avoir besoin d'un AkComponent. Cette fonctionnalité prend comme données d'entrée un Event et des données de transformation, enregistre un Wwise Game Object temporaire avec un numéro d'identification (ID) assigné, et déclenche l'Event à l'endroit et à l'orientation indiqués dans les données de transformation.
Comparativement à la création d'un AkComponent pour y assigner un Event, l'utilisation de la fonctionnalité « Post Event at Location » est une approche beaucoup moins coûteuse. Les Wwise Game Objects contiennent généralement très peu d'informations, mais se comportent de la même façon que les sons déclenchés sur un AkComponent. Les principales différences les distinguant sont que les Events déclenchés sur les Wwise Game Objects ne peuvent pas changer leurs données de transformation après le déclenchement de l'Event, ne peuvent pas être attachés à un autre Actor, ne peuvent pas profiter des Switches, States ou callbacks de Wwise, et ne peuvent pas être modifiés par des Game Parameters (paramètres de jeu) ayant un Scope (mode d'application) réglé sur « Game Object ».
Malgré ces limitations, déclencher des Events à un emplacement reste très utile pour de nombreux types de sons. Cette fonctionnalité est habituellement utilisée pour jouer des sons uniques (de type « fire-and-forget ») ou des boucles, lus de manière positionnelle. Les sons 2D non positionnels qui ne sont pas liés à un Actor ou à un emplacement peuvent également être joués à l'aide de cette fonction ; ces sons vont ignorer les données de transformation.
Dans Scars Above, nous avons beaucoup utilisé la fonctionnalité « Post Event at Location » pour les sons de l'interface utilisateur, la bande musicale, les interactions dans le monde du jeu, les Events d'impact (y compris certains sons de coups sur les ennemis), les Actors statiques émettant des sons en boucle, et bien plus encore. Les Events utilitaires de portée globale, tels que ceux qui définissent des States globaux, effectuent des changements de mixage général ou activent/désactivent des bus, sont également de bons candidats pour l'utilisation de cette fonctionnalité.
Lors de l'utilisation de la fonction « Post Event at Location », il convient de garder à l'esprit certains points :
1. Pour obtenir l'emplacement voulu où jouer un son, vous pouvez rechercher un Component ou un Actor fournissant les données de l'emplacement. Utilisez des fonctions telles que « Get World Location » (obtenir l'emplacement dans le monde) ou « Get Actor Location » (obtenir l'emplacement de l'Actor) pour récupérer les données de positionnement ;
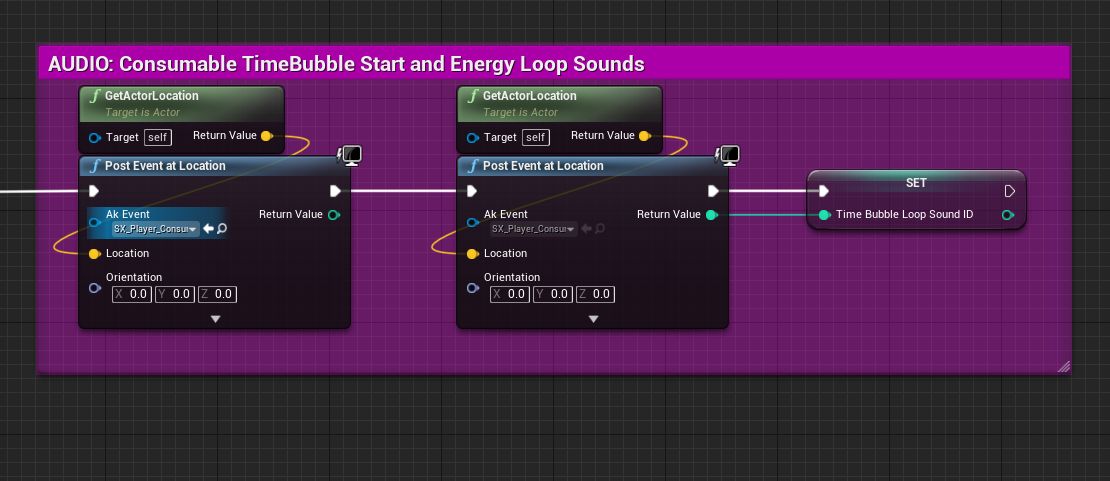
Image 25 : Déclenchement de sons positionnels à l'emplacement des Actors
2. Si vous déclenchez un son au moment du « BeginPlay » (début de jeu), assurez-vous que vos Actors de Spatial Audio soient chargés avant de déclencher l'Event. Cela permet de s'assurer que le son est correctement positionné dans le réseau Spatial Audio. Contrairement aux AkComponents, les Events joués sur un Game Object ne mettent pas à jour leur emplacement par rapport à Spatial Audio lorsque les Actors de Spatial Audio sont chargés.
3. Lorsque vous jouez des sons en boucle sur un Game Object plutôt que sur un AkComponent, vous devez également gérer l'arrêt de ces sons lus en boucle. La destruction d'un AkComponent (par exemple lorsque l'Actor parent est déchargé) arrêtera tous les sons acheminés à travers lui. Cependant, les Game Objects temporaires créés avec la fonctionnalité « Post Event at Location » ne sont pas liés à une telle logique de jeu. Pour arrêter les sons, vous pouvez soit désenregistrer le Game Object approprié, soit arrêter manuellement l'Event. La façon la plus simple d'arrêter l'Event d'un Game Object est d'appeler la fonction « Execute Action on Playing ID » (effectuer une action sur l'ID en lecture) avec l'ID du Game Object définie comme donnée d'entrée.
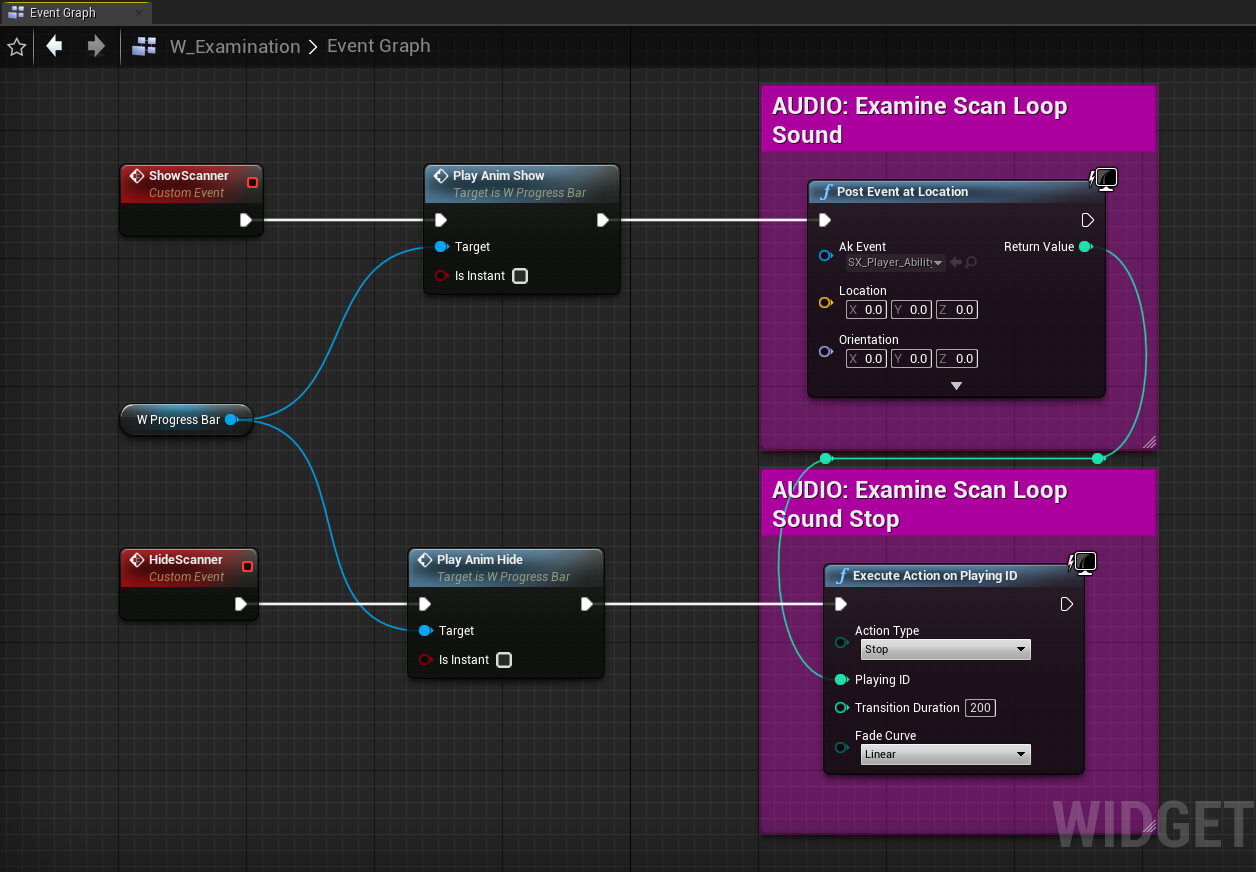
Image 26 : Déclenchement et arrêt d'un son d'interface utilisateur non positionnel
Notifications d'animation (Notifies)
Déclencher des Events directement dans les animations est une méthode courante que nous avons utilisée pour jouer des sons dans le jeu. Même si la plupart des sons ont été déclenchés sur le même AkComponent, nous avons eu des cas où un grand nombre de notifications concomitantes ont déclenché beaucoup de sons à jouer simultanément, résultant en la génération d'un grand nombre de voix physiques.
Diviser des sons en petits morceaux ou en couches multiples peut offrir une plus grande fidélité et un meilleur contrôle de la synchronisation avec le mouvement. Cependant, le déclenchement de ces sons en successions rapides peut conduire au déclenchement d'un nombre excessif d'Events, ce qui entraîne de nombreux appels à Wwise, en particulier si plusieurs animations similaires sont jouées en même temps.
Les zones de transitions (blend) peuvent encore aggraver le problème, car la superposition de deux animations comportant chacune un nombre important de notifications peut potentiellement déclencher un nombre encore plus élevé d'Events.
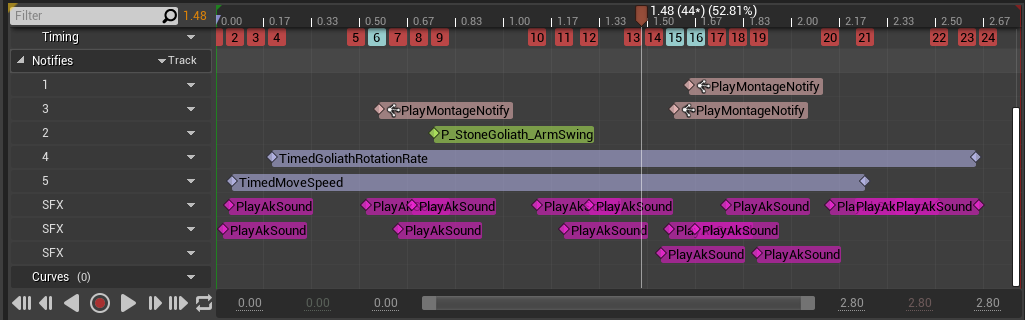
Image 27 : Montage d'une animation avec un grand nombre de notifications sonores
Dans de tels cas, nous devrions nous demander si le nombre élevé de notifications par animation est vraiment nécessaire et envisager la possibilité qu'un plus petit nombre d'Events audio permette d'atteindre un niveau de qualité similaire ou équivalent. En ayant moins de sons simultanés dans les animations, nous pouvons réduire le nombre de voix actives et alléger la charge CPU.
Organiser les assets pour une meilleure optimisation
L'organisation de nos assets est essentielle pour améliorer les performances et le flux de travail général de notre projet. En plaçant les assets dans des SoundBanks et des Sublevels (sous-niveaux) appropriés, nous pouvons contrôler le moment où ces assets doivent être chargés et déchargés. Cela nous permet de gérer l'utilisation des ressources de manière plus efficace, en veillant à ce que seuls les assets nécessaires soient chargés dans la mémoire à tout moment.
Il est également important de garder nos projets organisés et exempts d'assets en doublons. La suppression des assets inutiles permet non seulement d'éviter trop de désordre, mais aussi de minimiser la consommation de ressources mémoire et CPU.
SoundBanks
Regrouper les sons dans des SoundBanks est un excellent moyen de gérer la mémoire audio dans le jeu. Dans la plupart des cas, il n'est pas nécessaire d'avoir l'intégralité des sons chargés à tout moment, donc regrouper les sons et ne les charger que lorsqu'ils sont nécessaires est l'un des meilleurs moyens de réduire la charge mémoire, tout en gardant une vue d'ensemble claire de quand et comment les sons sont chargés et joués.
Afin de pouvoir charger correctement les différents types de sons, nous avons décidé de les regrouper dans les catégories suivantes :
- Main (catégorie principale) : Contient les Events qui seront utilisés tout au long du jeu ;
- Player (joueur) : Contient tous les Events du joueur ;
- Enemies (ennemis) : Une SoundBank par type d'ennemi, contenant tous les Events de cet ennemi ;
- CharactersCommon (communs aux personnages) : Contient tous les Events communs partagés entre les personnages ;
- Levels (niveaux) : Une SoundBank par Level (niveau) / Sublevel (sous-niveau), contenant tous les Events de ce Level / Sublevel ;
- LevelsCommon (communs aux niveaux) : Contient tous les Events communs partagés entre les niveaux ;
- Music (musique) : contient tous les Events de musique ;
- Voice (voix) : Contient tous les Events de dialogues ;
- EmotionalResponses (réponses émotionnelles) : Contient tous les Events des réponses émotionnelles du joueur ;
- Cinematic (scènes cinématiques) : Contient tous les Events des scènes cinématiques ;
- HapticFeedback (retours haptiques) : Contient tous les Events de retours haptiques.
- SoundBanks à chargement automatique (Auto-loaded SoundBanks)
Les SoundBanks réglée en « auto-load » sont chargées automatiquement lorsqu'un Event appartenant à cette SoundBank est référencé dans le jeu. Les SoundBanks comme Main, Player et Music sont constamment référencées et conservées en mémoire pendant toute la durée du jeu. Pour les SoundBanks d'ennemis, nous avons gardé une trace du moment et de l'endroit où chaque type d'ennemi est référencé, et nous nous sommes appuyés sur le système de chargement automatique pour charger et décharger dynamiquement les SoundBanks spécifiques à chaque type d'ennemi.
Dans notre projet, toutes les SoundBanks, à l'exception des SoundBanks de niveaux (Levels), sont réglées en auto-load. Pour les niveaux, nous voulions avoir un contrôle strict sur le moment et l'endroit où les Actors et les Events sont chargés. Nous avons lié le chargement des SoundBanks des niveaux au système de streaming (chargement et déchargement) de niveaux de la World Composition, qui nous permet de charger et de décharger des niveaux spécifiques en fonction des besoins (j'aborderai le streaming de niveaux plus loin dans cette section).
- SoundBanks communes
Nous avons créé des SoundBanks communes (Commons) pour stocker les Events partagés par différents personnages ou niveaux, et les avons configurées en auto-load. L'avantage des SoundBanks communes est que le média partagé n'est chargé qu'une seule fois au lieu d'être dupliqué dans plusieurs SoundBanks, ce qui permet de réduire la charge mémoire. En contrepartie, les SoundBanks communes n'étant pas liées à des personnages ou à des niveaux spécifiques, elles restent chargées plus longtemps que celles chargées automatiquement ou que celles contenant des assets en streaming.
L'alternative aux SoundBanks communes lors de l'utilisation d'Events partagés consiste à dupliquer les médias partagés dans différentes SoundBanks. Bien que cela puisse entraîner des moments pendant lesquels les mêmes Events sont chargés dans plusieurs SoundBanks, si celles-ci sont correctement gérées, ces moments peuvent finalement être moins fréquents qu'en utilisant des SoundBanks communes.
L'utilisation de SoundBanks communes est optimale si nous les utilisons pour stocker des Events dont nous savons qu'ils seront référencés par plusieurs personnages ou niveaux différents en même temps. Par exemple, si nous rencontrons différents groupes d'ennemis dans la même zone et partageant certains sons. L'autre approche est plus appropriée lorsque nous savons que les Events réutilisés ne seront pas chargés dans plusieurs SoundBanks en même temps, comme c'est généralement le cas avec les SoundBanks de niveaux. C'est au concepteur sonore de décider quand et comment charger les SoundBanks communes et spécifiques en fonction des besoins du projet et des situations particulières.
- Event-Based Packaging / SoundBanks auto-définies (Auto-Defined)
Scars Above a été développé en utilisant l'ancien système de SoundBanks, mais nous avons l'intention d'utiliser le système amélioré de SoundBanks auto-définies (Auto-Defined SoundBanks) pour tous les projets à venir. Les SoundBanks auto-définies, introduites dans la version 2022.1 de Wwise, s'appuient sur le concept d'Event-Based Packaging (packaging basé sur les Events) et visent à remplacer l'ancien système. Le principe derrière les SoundBanks auto-définies est de traiter chaque Event comme une SoundBank miniature autonome qui sera chargée seulement lorsque l'Event est référencé, et déchargée une fois qu'il a fini de jouer.
Pendant la production de Scars Above, nous avons tenté de passer au système d'Event-Based Packaging, mais nous avons rencontré de nombreux problèmes lors de l'implémentation de cette fonctionnalité. Bien que très prometteuse en théorie, cette fonctionnalité n'était, en pratique, pas suffisamment aboutie, et nous avons donc décidé de nous en tenir à l'ancien système de SoundBanks pour notre jeu.
Streaming de niveaux
En utilisant le streaming de niveaux (Level Streaming), nous pouvons nous assurer que seuls les Actors du niveau en cours et réellement nécessaires sont chargés en mémoire. Cela réduit le nombre d'Actors chargés simultanément, ce qui permet de réduire le nombre d'émetteurs et de Game Objects qui utilisent les précieuses ressources des threads audio.
Pour chaque émetteur situé dans un niveau et envoyé à Spatial Audio, les calculs des chemins de diffraction doivent être effectués chaque fois que le Listener se déplace. Cela se produit à chaque image, et le fait d'avoir des centaines d'émetteurs chargés peut provoquer de nombreux pics d'activité de Spatial Audio sur le CPU (voir l'image 3).
Nous pouvons profiler le nombre d'émetteurs actifs en tout temps dans le Profiler de Wwise. Selon mon analyse, il est recommandé de garder le nombre d'émetteurs (valeur « Spatial Audio - Emitters Processed » dans le Profiler) en dessous de 150 sur les plateformes de génération 8, et 200 sur les plateformes de génération 9 et PC.
La meilleure façon de réduire le nombre d'émetteurs est de diviser le niveau en sous-niveaux (Sublevels) plus petits et de ne les charger qu'en cas de besoin. Le fait de regrouper nos Actors dans des sous-niveaux dédiés à l'audio nous a permis de contrôler les zones où les Actors appartenant à ce niveau étaient chargés. Lorsque le joueur entre dans une zone désignée, les Actors appartenant à ce sous-niveau sont chargés, et lorsque le joueur sort de la zone, les Actors sont déchargés. Le système que nous avons utilisé dans Scars Above, permettant de charger et décharger des niveaux en fonction de leurs limites, s'appelle « World Composition » (composition du monde).
- World Composition
La World Composition est un système pour gérer les mondes de grande taille, où la carte du monde est divisée en sous-niveaux plus petits organisés en Stream Layers (couches de streams). Chaque sous-niveau possède son propre volume de délimitation, les Level Bounds (limites de niveau), et, en fonction du Stream Layer associé, se voit attribuer une valeur de distance de streaming en unités Unreal. Cette distance détermine la zone autour du volume de Level Bounds dans laquelle le sous-niveau sera chargé. Par exemple, si un volume de Level Bounds a une distance de streaming de 1500 unités, le niveau sera chargé à chaque fois que le joueur se trouvera à l'intérieur de ces 1500 unités de distance (ou à l'intérieur du volume).
Ce système permet d'efficacement diviser le monde en sections faciles à gérer, ce qui nous permet de ne charger que les Actors dont nous avons besoin dans une zone donnée. Bien que d'envoyer des sons dans le système de voix virtuelles puisse libérer une partie du traitement audio effectué par le CPU, l'Actor lui-même est toujours chargé, et son Game Object est enregistré pour le calcul du volume et de Spatial Audio. Le fait d'avoir trop de ces Game Objects en mémoire peut également provoquer des pics d'activité du CPU.
- Comment nous avons subdivisé les niveaux
Lorsque l'on divise un niveau en sous-niveaux plus petits, la chose la plus intuitive est de regrouper les Actors en fonction des zones spécifiques de notre monde auxquelles ils appartiennent. Ces zones représentent des parties du niveau qui sont suffisamment distinctes d'un point de vue acoustique et visuel pour être traitées comme des aires séparées lorsqu'il s'agit d'organiser les assets et de les nommer.
Chaque zone dispose d'un sous-niveau audio dédié. En fonction de la complexité et de la taille des zones, il peut être utile de les subdiviser davantage en niveaux plus petits.

Image 28 : Biome de marécage dans Scars Above avec délimitations des sous-niveaux audio
- Délimitations de niveau (Level Bounds)
Après avoir activé la World Composition, nous pouvons définir les limites de chaque sous-niveau que nous utiliserons pour le système de streaming de niveaux. Une instance de l'Actor Level Bounds utilisé pour délimiter ce niveau peut être trouvée dans le « World Outliner ». Ces Actors sont représentés par des boîtes transparentes (nous sommes limités à l'utilisation d'un cube, une forme de base qui ne peut pas être modifiée) et détermineront la zone couverte par chaque sous-niveau. Lors de la définition des limites d'un sous-niveau, il est important de se demander si le volume de délimitation englobe tous les sons et Actors qui appartiennent à ce sous-niveau.
La meilleure façon de déterminer les limites d'un sous-niveau est de sélectionner tous ses Actors et d'observer la zone qu'ils couvrent. En général, il est bon d'observer les sphères d'atténuation de nos Actors AkAmbientSound, puisqu'ils ont tendance à couvrir la plus grande surface du niveau.

Image 29 : Tous les Actors audio sélectionnés sur un sous-niveau
Les délimitations de niveaux doivent ensuite être ajustées pour englober les Actors sélectionnés, en tenant compte des sphères d'atténuation.
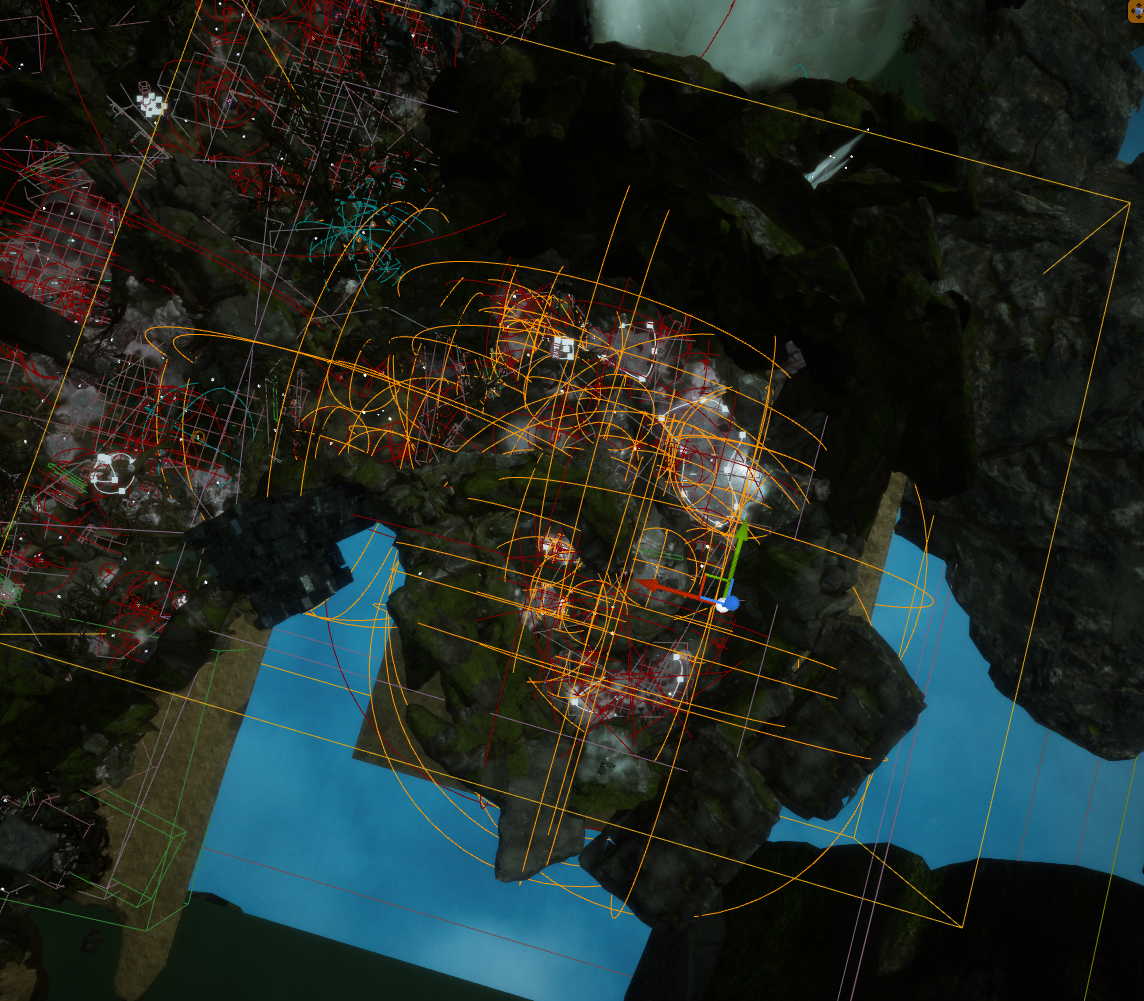
Image 30 : Volume de délimitation de niveau (Level Bounds) englobant tous les Actors audio d'un sous-niveau
- Stream Layers
Pour qu'un sous-niveau soit correctement chargé dans le système de stream, nous devons l'affecter à un Stream Layer. Pour ce faire, sélectionnez le sous-niveau dans la fenêtre Levels et choisissez le Stream Layer approprié.
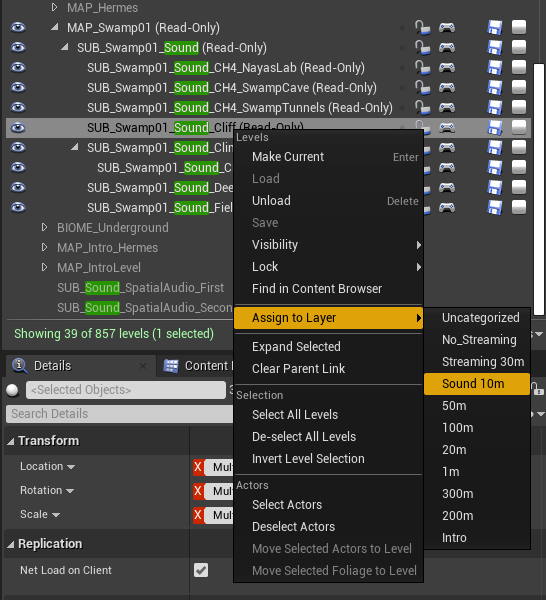
Image 31 : Assignation d'un sous-niveau audio au Stream Layer approprié
Dans la fenêtre World Composition, la sélection d'un Stream Layer nous permet de visualiser les limites de tous les niveaux assignés à ce Layer avec une vue de dessus.
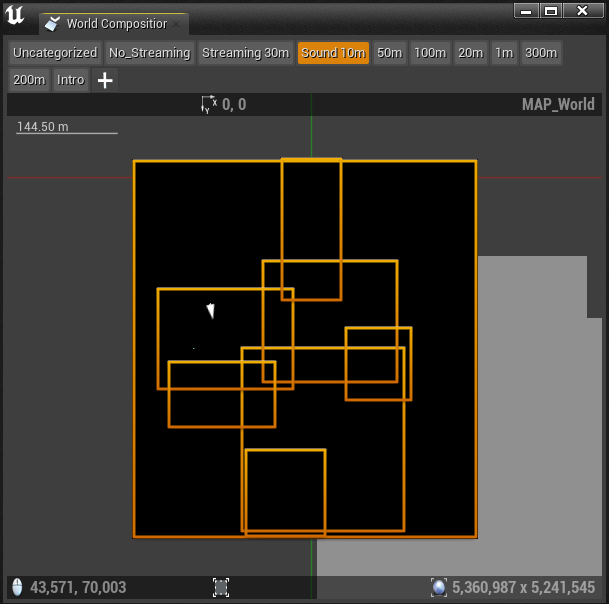
Image 32 : Fenêtre World Composition montrant les sous-niveaux assignés au Stream Layer « Sound 10m »
- AntiLevelStreaming
Vous avez peut-être déjà compris que l'utilisation d'une simple boîte pour couvrir une zone d'Actors à charger n'est peut-être pas la meilleure façon d'optimiser le chargement et le déchargement des sous-niveaux. En étant limités à la forme très simple d'un cube, nous sommes incapables de définir précisément les limites de notre sous-niveau. Cela donne lieu à des problèmes où nous pouvons avoir des zones sur la carte où plusieurs niveaux se chevauchent et sont chargés en même temps, juste parce que nous avons été incapables d'exclure des niveaux de cette zone en raison de la forme cubique de l'Actor de délimitations.
Dans les zones densément peuplées avec de nombreux Actors, même avec un placement correct des limites de niveau, nous pouvons toujours nous retrouver avec des zones sur la carte où il y a trop d'Actors chargés en même temps.
Pour résoudre ces problèmes, notre équipe de programmation a implémenté une solution personnalisée appelée AntiLevelStreaming, qui vient en complément de la World Composition.
En ajoutant des instances d'Actors AntiLevelStreaming sur la carte, nous pouvons créer des volumes de délimitation très similaires aux limites de niveau et assigner des sous-niveaux spécifiques que nous aimerions exclure du système de streaming de niveaux (c'est-à-dire décharger) lorsque nous entrons dans ces volumes. En utilisant ce système en juxtaposition avec la World Composition, nous avons résolu avec succès les problèmes de streaming de niveaux dans les zones où un nombre excessif de sous-niveaux étaient chargés en mémoire.
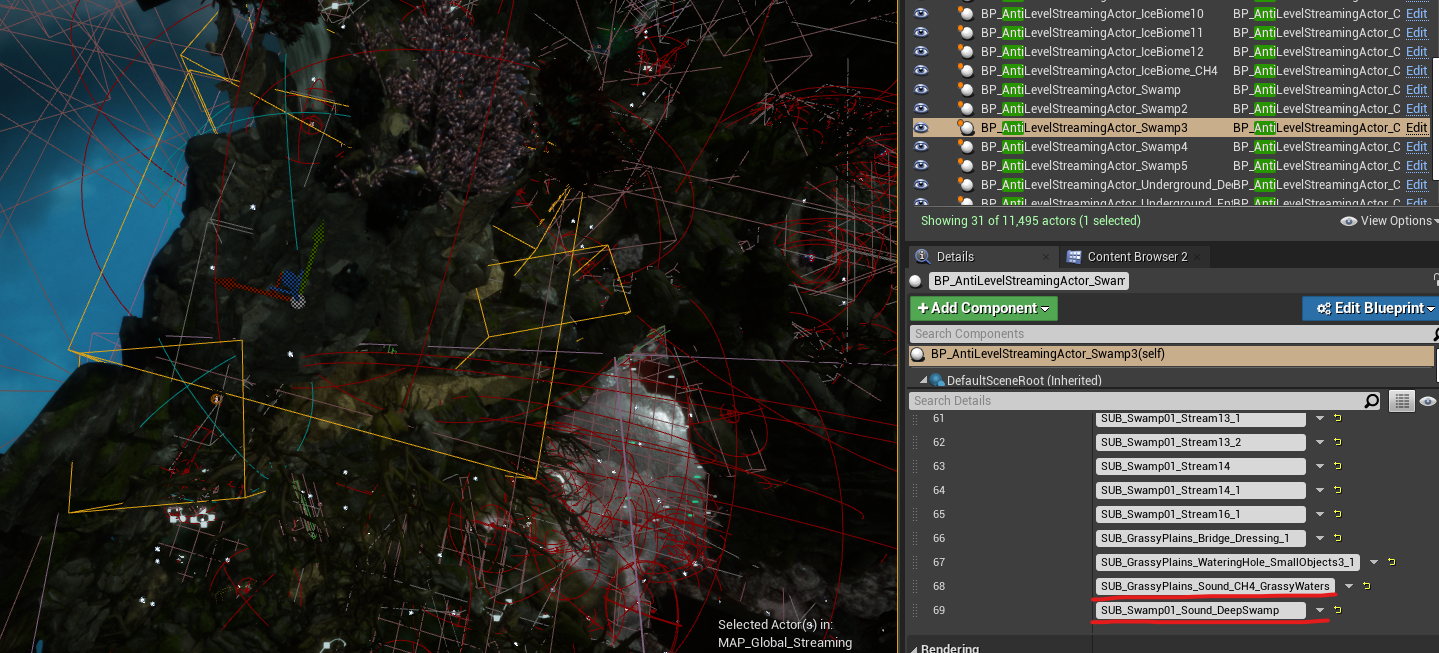
Image 33 : Actor AntiLevelStreaming avec assignation de sous-niveaux audio
- Streaming de Spatial Audio
Malheureusement, le streaming des Actors de Spatial Audio n'était pas une option. Nous avons déterminé par des tests que le chargement et le déchargement des volumes de Spatial Audio, et plus particulièrement des AkAcousticPortals, entraînaient un grand nombre de recalculs, ce qui pesait lourdement sur le processeur.
Au cours de ces tests, nous avons découvert que le chargement et le déchargement dynamiques des volumes de Spatial Audio et des AkAcousticPortals au moment de l'exécution du jeu avaient un impact significatif sur les performances du CPU. Pour chaque Actor de Spatial Audio qui était chargé ou déchargé du stream, les chemins de diffraction devaient être recalculés pour tous les Actors actifs. Il n'était donc pas possible de mettre en stream, avec d'autres assets audio, les Actors liés à Spatial Audio.
Pour résoudre ce problème, nous avons décidé de créer un sous-niveau persistant dédié à Spatial Audio contenant tous les Actors de Spatial Audio. Ce sous-niveau reste chargé en permanence, indépendamment du stream de niveaux.
Cela a entraîné des problèmes en fin de production en raison de la géométrie excessive de Spatial Audio (à un moment donné, nous nous sommes retrouvés avec plusieurs milliers d'Actors de Spatial Audio dans un sous-niveau persistant). Nous avons pu diviser ce sous-niveau en deux sous-niveaux plus petits et les charger uniquement lors de la transition entre des zones éloignées du jeu. Comme la transition était gérée par un écran de chargement, nous avons eu le temps de charger et de décharger correctement les sous-niveaux de Spatial Audio nécessaires sans affecter l'expérience du joueur.
Suppression des assets inutilisés
Dans tout projet se développant à long terme, certaines fonctionnalités peuvent devenir obsolètes ou changer radicalement, passant par plusieurs itérations avant que l'équipe ne parvienne à une solution adaptée. Les sons conçus pour ces fonctionnalités peuvent ne plus être utiles et de nouveaux sons devront être créés.
Lorsque plusieurs personnes travaillent sur le même projet, il n'est pas toujours possible de garder une trace de tous les changements et de toutes les versions des sons, et certains effets sonores peuvent devenir redondants, et ce à l'insu du concepteur sonore. Pour optimiser les ressources mémoire, il est important d'identifier et de supprimer les Events inutilisés.
La façon la plus simple de savoir si un AkEvent .uasset n'est pas utilisé est de vérifier ses références. Si l'Event n'a qu'une seule référence, qui est celle de sa SoundBank, il est probable qu'il ait été mal implémenté ou qu'il ne soit plus nécessaire. Dans ce cas, je recommande de supprimer l'Event inutilisé de la SoundBank et de le déplacer dans un dossier « Unused » (« inutilisé »), à la fois dans l'éditeur Unreal et dans Wwise. Cela permet de s'assurer que l'Event inutilisé ne consomme pas de mémoire dans le jeu, mais qu'il reste accessible pour une utilisation future si le besoin se présente.
Image 34 : Un AkEvent référençant uniquement sa SoundBank
SpatialAudio
Le système Spatial Audio est un vaste sujet que je n'aborderai pas dans ce document. Cependant, je l'ai couvert en détail dans mon précédent article, qui comprend des bonnes pratiques d'optimisation à appliquer pour Spatial Audio.
Lien vers la section Optimisation de l'article :
Optimisation de Spatial Audio
Dans cette section, vous trouverez tous les détails nécessaires à l'optimisation de Spatial Audio.
En résumé, les étapes clés de l'optimisation de Spatial Audio sont les suivantes :
- Avoir une géométrie aussi simple que possible en gardant un œil sur le nombre total de triangles ;
- Minimiser le nombre de volumes, et en particulier les AkAcousticPortals ;
- Désactiver les Surface Reflectors (réflecteurs de surface) sur tous les volumes convexes ;
- Faire attention au nombre total d'émetteurs traités à chaque image ;
- Ajuster les paramètres d'initialisation de Spatial Audio par plateforme.
Si vous souhaitez en savoir plus sur Spatial Audio, je vous recommande de parcourir le document et de vous référer à la documentation officielle d'Audiokinetic sur le sujet.
Ajustements mineurs (après application des autres solutions)
Si les solutions précédentes n'ont pas résolu vos problèmes, vous pouvez considérer ces quelques étapes supplémentaires pour vous permettre d'amener votre jeu à son aboutissement final.
Remplacer les Events « Stop » par la fonctionnalité « Execute Action on Event/ID »
Pour certains types de sons, il est nécessaire de créer et d'implémenter un Event « Stop » dédié.
Cependant, il est possible d'utiliser les fonctions Blueprint existantes appelées « Execute Action on Event » / « Execute Action on Playing ID ». Ces fonctions fournissent des actions telles que Stop ou Pause, pouvant être utilisées pour remplacer certains des Events responsables de l'arrêt ou de la mise en pause des sons. En utilisant ces fonctions d'Unreal Engine au lieu d'Events dédiés, nous pouvons complètement supprimer ces Events des SoundBanks. Cela permet de réduire la charge mémoire du projet, même si l'impact est relativement faible. Néanmoins, cela contribue à l'optimisation de notre jeu.
Remplacer les Actors-Mixers par des dossiers lorsque c'est possible
Dans les situations où les Actor-Mixers sont utilisés dans le projet Wwise uniquement pour organiser des sons, mais qu'aucun changement ou modification n'est fait sur ces Actor-Mixers, nous pouvons obtenir le même résultat en les remplaçant par de simples dossiers (« Virtual Folder »). Cela réduit le nombre de calculs nécessaires pour ces sons puisqu'il y a un niveau de hiérarchie de moins à franchir.
Comme pour le remplacement des Events « Stop », cette approche peut ne pas apporter d'améliorations significatives par rapport à d'autres techniques d'optimisation mais, dans certains cas, la moindre petite optimisation peut se révéler utile.
Réduire le nombre de variations à l'intérieur d'un Random Container
Si la limite d'une plateforme spécifique commence à être atteinte, il est possible de réduire la charge mémoire pour cette plateforme en excluant certains assets. Cela peut être facilement appliqué aux Random Containers, où nous pouvons choisir d'avoir moins de variations d'un son spécifiquement pour cette plateforme tout en conservant le nombre original de variations pour d'autres plateformes moins contraignantes.
Pour exclure des variations d'un Random Container, nous pouvons désolidariser (fonction « Unlink ») l'option « Inclusion » pour une variation spécifique, et exclure ce son de la plateforme que nous souhaitons optimiser. Ce faisant, nous pouvons réduire l'utilisation de la mémoire sur cette plateforme particulière tout en conservant le nombre original de variations de ce son sur les autres plateformes.
Conclusion
Merci d'avoir lu ce document. L'optimisation audio d'un jeu est effectivement une étape cruciale pour obtenir de bonnes performances et une utilisation efficace de la mémoire. En appliquant les différentes techniques d'optimisation présentées ici, nous pouvons espérer atteindre notre objectif d'améliorer la satisfaction globale des joueurs et leur permettre de s'immerger pleinement dans le jeu tout en profitant d'une expérience visuelle et auditive fluide et homogène.
Mes plus grands remerciements vont à Dimitrije, Teodora, Selena, Marko et Petar, mes collègues concepteurs sonores chez Mad Head Games, et à Nikola d'EA Dice, pour leur soutien et leurs commentaires. Un grand merci à Artem, notre programmeur audio, et à Olja, Lazar, Stefan et Borislav de l'équipe d'Assurance Qualité de Mad Head Games. Un grand merci à Julie, Masha et Maximilien, ainsi qu'à Damian d'Audiokinetic pour leurs commentaires et l'opportunité de publier mes résultats sous la forme de cet article.
Liens utiles
Cours de certification Wwise-251 :
https://www.audiokinetic.com/fr/courses/wwise251/
Documentation officielle sur le Profiler de Wwise :
https://www.audiokinetic.com/fr/library/edge/?source=Help&id=profiling
Brève description des paramètres du Profiler de Wwise :
https://www.audiokinetic.com/fr/library/edge/?source=Help&id=performance_monitor_settings#profiler_counters
Documentation sur les défaillances de voix (Voice Starvation) :
https://www.audiokinetic.com/fr/library/edge/?source=Help&id=ErrorCode_VoiceStarving
Court document sur le dépannage des défaillances de sources (Source Starvation) :
https://www.audiokinetic.com/fr/library/edge/?source=SDK&id=streamingmanager_tips.html#streamingmanager_tips_troubleshooting_sourcestarvation
Directives générales d'optimisations du CPU pour Wwise :
https://blog.audiokinetic.com/fr/wwise-cpu-optimizations-general-guidelines/
Optimisation de l'utilisation du CPU :
https://www.audiokinetic.com/fr/library/edge/?source=SDK&id=goingfurther_eventmgrthread.html
Conseils et bonnes pratiques de conversion :
https://www.audiokinetic.com/fr/library/edge/?source=Help&id=versions_tips_and_best_practices
Section de mon article sur l'optimisation de Spatial Audio :
https://blog.audiokinetic.com/fr/wwise-spatial-audio-implementation-workflow-in-scars-above/#optimization

Commentaires